(antal aktiva besökare uppdateras automatiskt var 4:e minut)

Citera denna sida som:
-
Logistisk regression
-
Först publiserad:
på:
Senast uppdaterad:
Om du vill informera om att denna webbsida finns...
Logistisk regression är en vanlig statistisk teknik och denna webbsida hjälper dig att förstå mer om det. Här hittar du även råd om du vill analysera din egen data med logistisk regression.
Du förstår denna webbsida bäst om du först har läst sidorna Introduktion till statistik, Observationer och variabler, Analytisk statistik, Sambandsanalys och Korrelation och regression.
Begreppet logistisk regression
Logistisk regression är en typ av linjär regression där den beroende variabeln (Y) inte är kontinuerlig (den saknar en ordning med ekvidistanta skalsteg). Alla variabler transformeras med hjälp av funktionen för naturliga logaritmer. En vanlig linjär regression genomförs där utfallet transformeras tillbaka med hjälp av inversen av naturliga logaritmer (t.ex. exponentialfunktionen). De betakoefficienter som produceras av den logistiska regressionen omvandlas ofta till oddskvoter (odds ratios). Logistisk regression skapar ekvationer som liknar de ekvationer som skapas av vanlig linjär regression:
Vanlig linjär regressionsekvation: Y = a + b1x1 + b2x2 + b3x3
Binar logistisk regressionsekvation: Log-odds = a + b1x1 + b2x2 + b3x3
X representerar de olika oberoende variablerna och b deras respektive betakoefficienter.
- The dependent variable is binary and the sample consists of independently chosen observations ⇒Unconditional binary logistic regression
- The dependent variable is binary and the sample consists of independently chosen matched pairs ⇒Conditional binary logistic regression
- The dependent variable is categorical with more than two categories / values and the sample consists of independently chosen observations ⇒Multinominal logistic regression (=multiclass logistic regression)
- The dependent variable is ordinal (has an order but not equidistant scale steps) and the sample consists of independently chosen observations ⇒ Ordered logistic regression (=ordinal regression = proportional odds model = ordered logit model)
Landskapet av logistiska regressionsmodeller
Möjliga olika situationer inom begreppet logistisk regression är:
| En beroende och en oberoende variabel (ett “y” och ett “x”) | Mer än en oberoende variabel (ett “y” och flera “x”) | Mer än en beroende variabel (flera “y” och en eller flera “x”) | |
|---|---|---|---|
| Den beroende variabeln är binär och urvalet består av oberoende valda observationer. | Icke-villkorad enkel logistisk regression (Unconditional simple logistic regression = unconditional unadjusted logistic regression = unconditional binary logistic regression = bivariate logistic regression) | Icke-villkorad multipel logistisk regression (Unconditional multiple logistic regression = unconditional multivariable logistic regression = unconditional adjusted logistic regression) | Icke-villkorad multivariat logistisk regression (Unconditional multivariate logistic regression) |
| Den beroende variabeln är binär och urvalet består av oberoende valda matchade par. | Villkorad enkel logistisk regression (Conditional simple logistic regression = conditional unadjusted logistic regression) | Villkorad multipel logistisk regression (Conditional multiple logistic regression = conditional multivariable logistic regression = conditional adjusted logistic regression) | Villkorad multivariat logistisk regression (Conditional multivariate logistic regression) |
| Den beroende variabeln är kategorisk med fler än två kategorier/värden och urvalet består av oberoende valda observationer. | Multinomial enkel logistisk regression (Multinomial simple logistic regression = multiclass simple logistic regression) | Multinomial multipel logistisk regression (=multiclass multiple logistic regression) | Multinomial multivariat logistisk regression (Multinomial multivariate logistic regression) |
| Den beroende variabeln är ordinal (har en ordning men inte ekvidistanta skalsteg) och urvalet består av oberoende valda observationer. | Ordnad enkel logistisk regression (Ordered simple logistic regression = ordinal simple logistic regression = ordered simple logit model) | Ordnad multipel logistisk regression (Ordered multiple logistic regression = ordinal multiple logistic regression = ordered multiple logit model) | Ordnad multivariat logistisk regression (Ordered multivariate logistic regression = ordinal multivariate logistic regression = ordered multivariate logit model) |
Det råder en begreppsförvirring där många felaktigt skriver “multivariat logistisk regression”, när de i själva verket har en enda y och flera x.
De oberoende variablerna (x) kan vara kategoriska (utan inbördes ordning), ordinala (ordnade) eller kontinuerliga (ordnade med ekvidistanta skalsteg). Resten av denna sida kommer att fokusera på icke-villkorad binär logistisk regression. Börja med att titta på denna video av Steve Grambow där han förklarar vad icke-villkorad binär logistisk regression är:
(Nedanstående video är på engelska. Om du har svårt att förstå engelska kan du få svensk text genom att klicka på “YouTube” (i nedre högra hörnet) för att gå till YouTube där videon automatiskt startar. I YouTube klickar du på kugghjulsikonen, sedan klicka på “Subtitles”, klicka sedan på auto-translate och välj svenska. Detta fungerar någorlunda bra men det kan bli en del felaktigheter i översättningen).
Det handlar inte om transporter – Den sanna historien bakom logistisk regression
I sin essä publicerad 1798 hävdade Malthus att medan livsmedelsproduktionen växer linjärt (1, 2, 3, 4, 5…), så växer befolkningen exponentiellt (1, 2, 4, 8, 16…), vilket oundvikligen leder till svält, sjukdom eller krig . På 1830-talet upptäckte den belgiske matematikern Pierre François Verhulst, som ville utmana Malthus skräckinjagande förutsägelse, att befolkningar inte exploderar i all oändlighet. Istället bromsas de in naturligt när resurserna minskar och bildar en elegant “S”-form som han mystiskt nog döpte till den “logistiska” kurvan.
Verhulsts arbete föll i glömska fram till 1920, då Raymond Pearl och Lowell Reed återupptäckte det för att modellera USA:s befolkningstillväxt. De väckte uppståndelse genom att förklara kurvan som en universell biologisk lag. De förespråkade den som en allmän lag för tillväxt och tillämpade den på allt från bananflugor till nationer, vilket utlöste en vetenskaplig feber. Men det fanns ett problem: ingen visste hur man skulle beräkna kurvans parametrar med precision förrän det brittiska geniet Sir Ronald A. Fisher ingrep. Fisher utvecklade “Maximum Likelihood-metoden” och tillhandahöll därmed den rigorösa matematiska motor som krävdes för att anpassa dessa komplexa modeller till verkliga data.
I nästan ett sekel var denna kurva enbart ett demografiskt verktyg, tills statistiker på 1940-talet, såsom Joseph Berkson, såg en dold briljans i dess geometri. Berkson insåg att denna “S”-form inte var perfekt för att räkna folkmängder, utan för att modellera sannolikheter – genom att omvandla linjära data till binära “ja eller nej”.
Varför logistisk regression är praktisk
Icke-villkorad binär logistisk regression lämpar sig utmärkt för att utvärdera sambandet mellan en given variabel och en dikotom beroende variabel. Många gruppjämförelser bör företrädesvis analyseras med logistisk regression snarare än med Chi-två- eller t-test. Skälet till att logistisk regression har fördelar gentemot enklare gruppjämförelser, såsom Chi-två och t-test, är:
- Möjligheten att justera för andra kovariater. Betydelsen av varje enskild variabel kan bedömas samtidigt som man justerar för inverkan av andra variabler. Detta ger oftast en mer rättvisande bild av variablernas verkliga betydelse.
- Det finns tekniker för att reducera antalet variabler så att endast de relevanta kvarstår. Detta minskar problemet med multipel testning (massignifikans).
Låt mig förklara den sistnämnda punkten med ett exempel. Anta att vi vill veta vilka variabler som skiljer sig mellan två grupper: de som har upplevt en sjukdom jämfört med de som inte har det (eller, till exempel, de som svarar “ja” på en fråga jämfört med de som svarar “nej”). Anta också att vi vill undersöka 50 olika variabler, varav vissa är kategoriska och andra kontinuerliga. Att använda Chi-två- eller t-test för att jämföra de två grupperna skulle resultera i 50 p-värden, där vissa ligger under och andra över 0,05. Ett p-värde under 0,05 kan dock uppstå av en slump. För att kompensera för risken att finna statistisk signifikans av ren slump, måste vi sänka gränsvärdet för vad vi betraktar som ett signifikant fynd. Det finns flera sätt att göra detta på. Exempelvis skulle en enkel Bonferroni-korrigering innebära att endast p-värden under 0,001 bör betraktas som statistiskt signifikanta (0,05 / 50 = 0,001). En konsekvens av detta är att mycket få, eller kanske inga, av de beräknade p-värdena skulle bedömas som statistiskt signifikanta.
Genom att använda logistisk regression på det sätt som beskrivs nedan, mildras detta problem. Man använder först en teknik som sorteringsmekanism för att avgöra vilka variabler som ska inkluderas i det andra steget: en multipel regression. Ett vanligt scenario är att man startar med 50 oberoende variabler. Det är rimligt att anta att endast 2–5 variabler kommer att kvarstå som statistiskt signifikanta i den slutliga modellen. Anta att vi slutligen landar på 5 p-värden (och oddskvoter). Enligt Bonferroni kan nu ett p-värde under 0,01 betraktas som statistiskt signifikant (0,05 / 5 = 0,01). Följaktligen har vi väsentligt minskat problemet med multipel testning.
De två argumenten för att använda multipel logistisk regression (när den beroende variabeln är dikotom) istället för en enkel gruppjämförelse, gäller även för multipel vanlig linjär regression (om den beroende variabeln är kontinuerlig) och multipel Cox-regression (om en tidsfaktor är den beroende variabeln).
Hur gör man i praktiken?
Börja med att titta på den här introduktionsvideon om hur man gör logistisk regression i programmet SPSS:
Förutsättningar som ditt datamaterial måste uppfylla
- Alla dina observationer är valda oberoende av varandra. Detta innebär att dina observationer inte ska vara grupperade på ett sätt som kan ha inflytande på utfallet. (Du kan ha grupperade observationer och justera för detta, men det är mer komplicerat vid logistisk regression och kan inte göras i alla statistikprogram).
- Du har tillräckligt många observationer för att undersöka din frågeställning. Antalet observationer du behöver bör uppskattas i förväg genom en beräkning av urvalsstorlek (sample size calculation).
- Den beroende variabeln är en binär klassvariabel (endast två alternativ). Vanligtvis beskriver denna variabel om ett fenomen existerar (kodat som 1) kontra inte existerar (kodat som 0). Ett exempel kan vara om en patient har en sjukdom eller om en specifik händelse inträffade.
- Kategoriska variabler måste vara ömsesidigt uteslutande. Detta innebär att det måste vara tydligt om en observation ska kodas som 0 eller 1 (eller något annat om den kategoriska variabeln har fler än två värden).
- Det bör finnas en rimlig variation mellan den beroende variabeln och de kategoriska oberoende variablerna. Du kan kontrollera detta genom att göra en korstabell mellan utfallsvariabeln och de kategoriska oberoende variablerna. Logistisk regression kan vara olämplig om det finns celler i korstabellen med få eller inga observationer.
- De oberoende variablerna korrelerar inte för mycket med varandra, i det fall du har fler än en oberoende variabel. Detta fenomen kallas multikollinearitet. Du bör testa för detta när du gör en multipel binär logistisk regression.
- Alla kontinuerliga oberoende variabler måste ha ett linjärt samband med logiten av den binära beroende variabeln. Den konstruerade modellen kommer inte att ha god anpassning om det finns ett icke-linjärt samband, såsom ett polynomsamband. Du behöver inte testa för detta innan du gör den logistiska regressionen, men att kontrollera detta bör vara en del av proceduren när du genomför regressionen.
Säkerställ att alla variabler är kodade på ett sätt som underlättar tolkningen av resultaten. Särskild uppmärksamhet bör ägnas åt kategoriska variabler för att säkerställa att kodningen är rimlig. Vid analys av exempelvis etnicitet måste du avgöra om du ska behålla en separat kategori för varje alternativ eller om du ska slå samman dem till större grupper. Detta beslut avgörs av ditt forskningsfokus och datamaterialets karaktär. Det är ofta värt att överväga om en sammanslagning av flera kategorier till endast två grupper kan förenkla tolkningen av resultatet.
Förberedelser
- Datarensning: Gör en frekvensanalys för varje variabel, var för sig. Du kommer sannolikt att hitta några överraskningar, såsom ett fåtal individer med ett tredje kön, en person med orimlig ålder, eller mer bortfall än förväntat. Gå tillbaka till källan och korrigera alla fel. Kontrollera alla berörda variabler efter korrigeringen genom att göra en ny frekvensanalys. Detta måste göras noggrant innan du fortsätter.
- Undersök spår av potentiell bias (snedvridning): Titta på andelen bortfall (missing data) för varje variabel. Det förekommer nästan alltid visst bortfall. Är bortfallet stort i vissa variabler? Har du en rimlig förklaring till varför? Kan det vara ett tecken på att det finns en inbyggd bias (systematiskt fel i urvalet av observationer/individer) i din studie som kan påverka utfallet?
- Justera oberoende variabler för att underlätta tolkning: Ganska ofta behöver några variabler transformeras till nya variabler. Det är oftast lättare att tolka resultatet av en logistisk regression om de oberoende variablerna antingen är binära eller kontinuerliga. En kategorisk variabel med flera alternativ kan tjäna på att antingen slås samman till en binär variabel eller delas upp i flera binära variabler. För kontinuerliga variabler kan det ibland vara lättare att tolka resultatet om du ändrar skalan. Ett typiskt exempel är att det ofta är bättre att transformera ålder i år till en ny variabel som visar ålder i decennier (tiotal år). När du vill tolka effekten av ålder är en ökning med ett år ofta ganska liten, medan en ökning med ett decennium oftast är mer kliniskt relevant (åtminstone för vuxna). Du kan se i tabell 4 i publikationen av Hargovan et al att oddskvoten för ålder anges per decennium och inte per år för att göra den mer meningsfull. Ett annat exempel är systoliskt blodtryck, där det kan vara vettigt att beräkna oddskvoter för en förändring på 10 mmHg snarare än 1 mmHg. Många laboratorieanalyser (blod- eller urinprov) kan också bli lättare att tolka genom att ändra skalan från en liten enhet till en större.
- Välj strategi: Gör en enkel (ojusterad) binär logistisk regression om du bara har en oberoende variabel. Om du däremot har flera oberoende variabler behöver du välja en strategi för hur dessa ska inkluderas i analysen. Det finns några olika sätt att göra detta på. Det första tillvägagångssättet (4a) är det bästa. Det är dock inte alltid genomförbart, så du kan behöva använda en annan strategi..
- Bestäm dig för att använda en fastställd kombination av oberoende variabler baserat på logiska resonemang/teorier (expertråd). Antalet oberoende variabler bör inte vara för stort, helst färre än 10. Detta är den föredragna metoden om du har en rimligt god teori om hur variablerna hänger ihop.
- Gör en multipel regression med alla tillgängliga oberoende variabler utan att ha någon teori om huruvida dessa variabler är meningsfulla. Detta kan fungera om du bara har ett fåtal variabler. Om du har många variabler kommer det sannolikt att resultera i en slutmodell som innehåller många oanvändbara variabler som mest utgör “brus”. Undvik därför att göra detta.
- Om du har många oberoende variabler och ingen teori om vilka som är användbara, kan du låta datorn föreslå vilka variabler som är relevanta att inkludera. Detta brukar kallas för en “fisketur” (fishing expedition). Du kan läsa mer om detta nedan..
Bygga en multivariabel model – från förutbestämd teori
Att bygga en logistisk modell där du själv, snarare än ett datorprogram, avgör vad som ska inkluderas är den metod som förordas. Videon nedan beskriver hur man bygger en sådan modell i SPSS, i enlighet med punkt 4a ovan:
Bygga en multivariabel model – fishing expedition
Här beskrivs hur man bygger en modell enligt punkt 4c ovan. Denna metod kan starta med en stor mängd oberoende variabler (utan någon egentlig övre gräns) och rensar bort de som är av mindre betydelse. Metoden brukar även kallas för en “fisketur” (fishing expedition). Det är inget fel med det, men det är viktigt att förhålla sig skeptisk till statistiskt signifikanta fynd som verkar märkliga. Många statistikprogram har automatiserade funktioner för detta. Det finns flera olika metoder:
- Forward inclusion/selection (Framåtval): Kan användas om du har fler variabler än observationer. När en variabel väl har lagts till stannar den oftast kvar i modellen. Metoden kanske väljer variabel A först för att den ser bra ut på egen hand, men missar att variabel B och C tillsammans hade varit en mycket bättre prediktor. Den misslyckas ofta med att fånga upp komplexa samband som bara syns när flera variabler samspelar. Metoderna nedan är bättre.
- Backwards elimination (Bakåt-eliminering): Användbart om du har fler observationer än variabler.
- Stepwise regression (Stegvis regression): Detta är en hybrid. Den börjar oftast som forward selection (lägger till variabler), men vid varje steg kontrollerar den bakåt för att se om någon variabel som tidigare lagts till nu blivit icke-signifikant (kanske för att den nya variabeln förklarar samma sak bättre). Detta åtgärdar den största bristen hos forward selection. Om variabel A lades till tidigt men blev överflödig när variabel C lades till, kommer den stegvisa regressionen att kasta ut variabel A igen. Den är mer flexibel och bättre än både “Forward inclusion/selection” och “Backwards elimination”. Titta på denna video av Brandon Foltz som introducerar konceptet: https://www.youtube.com/watch?v=An40g_j1dHA (på engelska men du kan få svensk textning).
- Regulariseringstekniker såsom LASSO-regression, Ridge-regression och Elastic Net: Dessa metoder kan även kallas för “penalized regression” (straffad regression) eller “regularized regression”. Stegvis regression medför en risk för överanpassning (overfitting) av din modell till just dina specifika observationer. Regulariseringstekniker löser detta problem genom att införa ett straff (penalty) för komplexa modeller. De anses numera vara överlägsna konventionell stegvis regression . Av dessa modeller är Elastic Net kanske den bästa, och den kan utföras i R, STATA och SPSS (i de nyare versionerna). Läs mer om detta på sidan om regulariserad regression.
Några praktiska råd:
- Om du insisterar på att använda stegvis regression (stepwise regression) måste du först kontrollera alla oberoende variabler för “nollte ordningens korrelationer” (zero order correlations). Detta innebär att kontrollera om några av de oberoende variablerna av potentiellt intresse korrelerar starkt med varandra. Om så är fallet måste du göra ett val innan du går vidare. Det finns ingen knivskarp definition av vad som utgör en “stark korrelation”. Jag föreslår att två oberoende variabler som har en Pearson- (eller Spearman-) korrelationskoefficient över +0,7 eller under -0,7 med ett p-värde <0,05 bör betraktas som alltför korrelerade. Om så är fallet måste du utesluta en av dem från vidare analys. Detta val bör styras av vad som är mest praktiskt att behålla i den fortsatta analysen (vad som sannolikt är mest användbart). Det bästa sättet att göra detta i SPSS är att göra en vanlig multipel linjär regression och under knappen Statistics kryssa i att du vill ha Covariance matrix och Collinearity diagnostics. Bortse från all annan utdata förutom dessa två.
- Om du använder regulariseringstekniker behöver du inte oroa dig för korrelation mellan oberoende variabler. Dessa regulariserings-regressioner är oftast bättre på att avgöra vilka variabler som ska behållas än om vi försöker göra det själva (såvida vi inte har en välgrundad teori om vilka variabler som bör inkluderas).
Utvärdera din logistiska modell
Modeller utvärderas ofta utifrån deras förmåga att separera (eller korrekt diagnostisera) individer (kallat diskriminering) eller huruvida de förutsagda sannolikheterna överensstämmer med det observerade utfallet (kallat kalibrering) . God diskriminering är mycket viktigt när man utvärderar en diagnostisk modell, medan god kalibrering är viktigt vid utvärdering av modeller som syftar till att förutsäga en framtida händelse . Det finns även mått på den nya modellens övergripande prestanda (overall performance). Diskriminering, kalibrering och övergripande prestanda hänger till viss del ihop, så en utmärkt modell har vanligtvis både hög diskriminering och god kalibrering, samt en god övergripande prestanda. De vanligaste måtten för att skatta en modells värde, anpassade efter Steyerberg et al , är:
- Övergripande prestanda (Overall performance):
- Cox och Snells R-kvadrat (Cox and Snell R Square): Detta är en typ av “pseudo R-kvadrat”-mått. Ett högre värde är bättre.
- Nagelkerkes R-kvadrat (Nagelkerke R square): Detta är en justerad version av Cox och Snells R-kvadrat. Många statistikprogram levererar detta värde om du kryssar i rätt ruta när du beställer en logistisk regression. Det beskriver hur väl variationen i den beroende variabeln förklaras av variationen i de oberoende variablerna. Noll innebär att den nya modellen är oanvändbar och 1,0 att den är helt perfekt. Följaktligen är ett högre värde bättre. En enkel och rimlig (om än inte helt korrekt) översättning är att ett värde på 0,10 innebär att ungefär 10 % av variationen i den beroende variabeln är associerad med variationer i de inkluderade oberoende variablerna. Om Nagelkerke ligger under 0,1 betyder det att din modell endast förklarar en liten del av variationen i den beroende variabeln. En bra modell har typiskt ett Nagelkerke R-kvadrat på >0,2 och ett värde >0,5 indikerar en utmärkt modell.
- Diskriminering (Discrimination):
- Sensitivitet, specificitet och prediktivt värde: Dessa beräknas för ett givet gränsvärde (cut-off) för sannolikheten att ha utfallet. Dessa värden kan presenteras för vilket gränsvärde som helst, men det vanligaste är en 50-procentig sannolikhet för utfallet.
- ROC-analys (Receiver Operating Characteristic): En utvidgning av sensitivitet och specificitet. Analysen beräknar sensitivitet och specificitet för alla möjliga gränsvärden gällande sannolikheten för utfallet. Titta på värdet för “Area Under the Curve” (AUC). Detta går vanligtvis från 0,5 (modellen är lika bra som ren slump) till 1,0 (modellen är perfekt). AUC kallas även för konkordans-statistik eller “c-statistics”. Ett AUC mellan 0,50–0,60 indikerar att din modell knappt är bättre än slumpen (vilket är dåligt). Ett AUC över 0,80 indikerar vanligtvis att din modell är ganska bra. Ett AUC över 0,90 är absolut utmärkt. OBS: ROC-analys är en separat analys som kräver att du sparar den skattade sannolikheten för händelsen för varje observation när du gör den logistiska regressionen.
- Diskrimineringslutning (Discrimination slope).
- Kalibrering (Calibration):
- Omnibus Tests of Model Coefficients (tillhandahålls av IBM SPSS). Ett lågt p-värde indikerar en bra modell (signifikant bättre än nollmodellen)..
- Hosmer och Lemeshow-test: Undersöker om den nya modellen beskriver observationerna bättre än ren slump (god anpassning). Ett lågt p-värde (< 0,05) indikerar att modellen har dålig anpassning (signifikant avvikelse från data). Ett högt p-värde (> 0,05) säger att din modell har god kalibrering.
- Kalibreringslutning (Calibration slope).
- Reklassificering (Reclassification):
- Reklassificeringstabell (Reclassification table).
- Reklassificeringskalibrering (Reclassification calibration).
- Net Reclassification Index (NRI).
- Integrated Discrimination Index (IDI).
- Klinisk användbarhet (Clinical usefulness)
- Nettonytta / Net Benefit (NB).
- Beslutskurveanalys / Decision curve analysis (DCA).
De vanligaste måtten på modellvaliditet är Nagelkerkes R-kvadrat, ROC-analys samt Hosmer och Lemeshows test. Mått för att skatta “Reklassificering” och “Klinisk användbarhet” är av nyare datum och används därför ännu inte i så stor utsträckning . Alla ovanstående tester för modellvalidering kan tillämpas på lite olika sätt:
- Oftast använder man 100 % av observationerna för att skapa modellen och använder sedan samma 100 % för att validera den. Detta kallas intern validering och bör alltid redovisas.
- Du kan använda 70–75 % av observationerna för att konstruera modellen och 25–30 % av dem för att testa modellen. Detta kan vara en god idé om du har många observationer (ibland kallat split-sample validation).
- Det ultimata testet är att applicera modellen på en annan uppsättning observationer som hämtats från en annan plats eller kontext . Att validera modellen i denna nya uppsättning observationer ger en uppskattning av hur användbar modellen är utanför den miljö där den konstruerades. Detta kallas extern validering. Utmärkta modeller uppvisar god total prestanda med hög diskriminering och kalibrering vid både intern och extern validering. Att uppnå detta är mycket sällsynt.
Att förstå resultatet av en logistisk regression
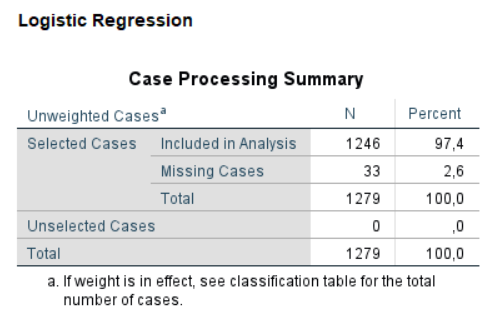
Logistisk regression handlar om att beräkna hur en eller flera oberoende variabler är associerade med en beroende variabel, där den sistnämnda alltid är dikotom. För varje variabel är det sannolikt att du har visst bortfall (missing data). Om du gör en multipel logistisk regression (med fler än en oberoende variabel) kommer detta bortfall att ackumuleras. Följaktligen kan du ha 10 % bortfall i en variabel och 10 % i en annan. De 10 % av observationerna som saknar data i en variabel kan dock vara andra observationer än de som saknar data i en annan variabel. Därför kan 10 % bortfall i en variabel och 10 % bortfall i en annan i värsta fall summeras till 20 %, och så vidare. Av denna anledning är det viktigt att kontrollera den totala andelen observationer som inte kunde användas i denna multipla logistiska regression.
Låt oss titta på ett exempel där vi vill undersöka hur kön, ålder, rökning och snusanvändning (oral tobak) korrelerar med upplevd hälsa . Se bilden ovan där totalt 2,6 % av observationerna inte kunde användas eftersom de hade bortfall i minst en av variablerna. En stor andel bortfall är oroväckande och kan potentiellt vara ett tecken på något systematiskt problem som behöver klargöras. 2,6% som i detta exempel är inget problem.

Upplevs hälsa i detta exemplet mäts med dimensionen ‘fysisk funktion’ i livskvalitetsenkäten SF-36. Den beroende variabeln mäts med en ordinalskala men har dikotomiserad vid nivån för den genomsnittliga upplevda hälsan hos den friska svenska befolkningen. Följaktligen innebär en 1:a bättre hälsa än genomsnittet, medan en 0:a innebär hälsa som är lika med eller lägre än genomsnittet.
I bilden till höger kan vi se att den beroende variabeln från början mättes med en ordinalskala som omvandlats till en ny variabel genom att införa ett gränsvärde (cut-off). Det är viktigt att förstå att variabler som ursprungligen var 88–100 kodas som 1 och värden 0–87 som 0 i denna regression. Det innebär att oddskvoterna predicerar (förutsäger) ett högre värde på den beroende variabeln snarare än tvärtom. Vi kan också se att för kön (gender) valde programvaran att koda kvinnligt kön som 1 och manligt som 0. Detta innebär att oddskvoten för den oberoende variabeln kön anger hur oddset för att vara kvinna hänger samman med att ha det högre poängintervallet i den beroende variabeln.
Det är avgörande att kontrollera hur de beroende och oberoende variablerna är kodade. Oberoende variabler som mäts på intervall- eller kvotskala kodas vanligtvis automatiskt med sina faktiska värden. Alltså är värdet 5 lika med 5 i regressionsanalysen. Detta är inte alltid fallet med variabler som mäts på en nominalskala. Du måste undersöka hur detta kodas av din programvara eftersom det avgör hur resultatet ska tolkas.
Den logistiska regressionen resulterar i en oddskvot (Odds Ratio) för var och en av de oberoende variablerna. Oddskvoten kan vara allt från 0 och uppåt mot oändligheten. En oddskvot kan aldrig vara under noll.
- Oddskvot = 1,0: Den oberoende variabeln är inte korrelerad med variationen i den beroende variabeln.
- Oddskvot > 1,0: En ökning av den oberoende variabeln är associerad med en ökning av den beroende variabeln (det är mer sannolikt att utfallet blir en 1:a snarare än en 0:a).
- Oddskvot < 1,0: En ökning av den oberoende variabeln är associerad med en minskning av den beroende variabeln (det är mer sannolikt att utfallet blir en 0:a än en 1:a).
Titta på bilden nedan. B är beta-koefficienten (liknande den i vanlig linjär regression). Beta-koefficienten kan anta vilket värde som helst från minus oändligheten till plus oändligheten. B-koefficienten transformeras också till en oddskvot och denna programvara (SPSS) benämner den “Exp(B)”. Oddskvoten är 1,0 när B-koefficienten är noll. De två kolumnerna till höger visar 95 % konfidensintervall för oddskvoten. Utifrån detta kan vi göra följande tolkningar:
- Kvinnligt kön är associerat med en minskad chans att ha höga poäng (oddskvoten är under 1,0).
- Stigande ålder är associerat med en minskad chans att ha höga poäng (oddskvoten är under 1,0). Åldern anges här i decennier, så vi får oddskvoten för en åldersökning på ett decennium.
- Rökning är associerat med en minskad chans att ha höga poäng (oddskvoten är under 1,0). Rökning anges här i enheter om 10 “paketår” (pack years), så vi får oddskvoten för en ökning med 10 paketår.
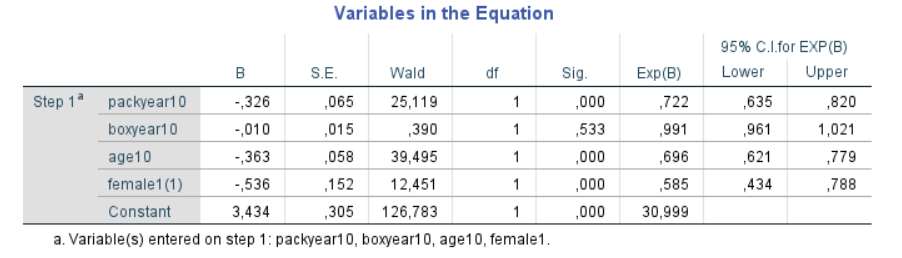
Studien i detta exempel visade att sämre självupplevd hälsa var förknippat med rökning, högre ålder och att vara kvinna, där det sistnämnda hade den lägsta oddskvoten för att ha god hälsa.
Nedan finns en video som visar ett annat exempel på logistisk regression och hur man tolkar resultatet:
(Nedanstående video är på engelska. Om du har svårt att förstå engelska kan du få svensk text genom att klicka på “YouTube” (i nedre högra hörnet) för att gå till YouTube där videon automatiskt startar. I YouTube klickar du på kugghjulsikonen, sedan klicka på “Subtitles”, klicka sedan på auto-translate och välj svenska. Detta fungerar någorlunda bra men det kan bli en del felaktigheter i översättningen).
Att presentera resultatet av en logistisk regression
Resultat från multivariabel binär logistisk regression bör alltid presenteras i en tabell där den första kolumnen listar alla utvärderade oberoende variabler, medan de följande kolumnerna redovisar regressionens utfall. Om datan är lämplig kan resultaten dock även presenteras som en användarvänlig uppslagstabell eller ett sannolikhetsnomogram. Uppslagstabeller kan vara ett bra alternativ om du enbart har dikotoma oberoende variabler kvar i den slutliga modellen. Sannolikhetsnomogram är ofta ett bra alternativ om du har en kontinuerlig variabel kvar i den slutliga modellen (se exempel nedan). Om du landar i en slutlig modell med flera kontinuerliga variabler är alternativen:
- Presentera helt enkelt data i en tabell (se praktiska exempel nedan). Detta måste göras oavsett, och det är inte alltid en bra idé att göra mer än så.
- Undersök konsekvenserna av att dikotomisera alla oberoende kontinuerliga variabler utom en. Ibland sjunker modellens förklaringsgrad (mätt med Nagelkerkes R-kvadrat och AUC) endast marginellt med några få procent. Detta “pris” kan vara acceptabelt för att kunna presentera ett komplicerat fynd på ett betydligt mer användarvänligt sätt. Om så är fallet möjliggör det att du skapar ett användarvänligt sannolikhetsnomogram. Detta är ofta värt att undersöka.
- Skapa ett komplicerat sannolikhetsnomogram (vilket sannolikt inte blir användarvänligt).
- Skapa en webbaserad kalkylator där användaren matar in information och en sannolikhet beräknas, eller gör en app som utför alla beräkningar när användaren matar in data. Detta fungerar oftast bra även om du har flera oberoende variabler som mäts på en kontinuerlig skala..
Praktiska exempel på presentation av resultat från multivariabel logistisk regression:
- Antimicrobial resistance in urinary pathogens among Swedish nursing home residents : Tabell 4 visar hur man kombinerar resultatet av flera bivariata (=univariata) logistiska regressioner och en efterföljande multivariabel logistisk regression i en och samma tabell.
- Prognostic factors for work ability in women with chronic low back pain consulting primary health care: a 2-year prospective longitudinal cohort study : Tabell 4 visar hur man kombinerar resultatet av flera bivariata (=univariata) logistiska regressioner och en efterföljande multivariabel logistisk regression i en enda tabell. Denna publikation demonstrerar också hur resultatet i en multipel binär logistisk regression kan presenteras som sannolikhetsnomogram (Figur 2). Det sistnämnda rekommenderas om din slutliga modell endast innehåller en kontinuerlig variabel och ett begränsat antal kategoriska variabler. Prediktiva nomogram kan konstrueras även för modeller som har fler än en kontinuerlig variabel, men de tenderar att bli komplicerade och mindre intuitiva.
- Predicting conversion from laparoscopic to open cholecystectomy presented as a probability nomogram based on preoperative patient risk factors : Tabell 2 visar hur man kombinerar resultatet av flera bivariata (=univariata) logistiska regressioner och en efterföljande multivariabel logistisk regression i en enda tabell. Denna publikation demonstrerar också hur resultatet i en multipel binär logistisk regression kan presenteras som sannolikhetsnomogram (Figur 1–4). Detta manuskript anger också tydligt att de bivariata regressionerna endast betraktas som en sorteringsmekanism och att utfallet av dem inte betraktas som ett resultat. Det anger att endast de kvarvarande variablerna i den multivariabla regressionen utgör det faktiska resultatet (och justerar signifikansnivån i enlighet med detta).
- Predicting the risk for hospitalization in individuals exposed to a whiplash trauma : I detta exempel innehåller den slutliga regressionsmodellen inga kontinuerliga variabler. Därav har en uppslagstabell konstruerats (Tabell 3). Tabell 3 konstruerades genom att rangordna de predicerade sannolikheterna för alla möjliga kombinationer (permutationer) av de slutliga prediktorerna.
Mer information
- Restore – Modul 4: Binär logistisk regression (Jag rekommenderar att du tar en titt här)
- Julie Pallant. Logistic regression. i SPSS survival manual. (Extremt användbar om du använder SPSS)
- Rekommendationer för bedömning och rapportering av multivariabel logistisk regression