(antal aktiva besökare uppdateras automatiskt var 4:e minut)

Om du vill informera om att denna webbsida finns...
Den här webbsidan beskriver signifikansnivå och hur det förhåller sig till p-värden. Dessa begrepp blandas ibland ihop, och genom att läsa den här sidan kommer du att förstå skillnaden. Sidan innehåller även onlinekalkylatorer till din hjälp.
Du kommer att förstå innehållet bäst om du först har läst Introduktion till statistik och Analytisk statistik.
Skillnaden mellan signifikansnivå (alfa) och p-värdet
(Nedanstående video är på engelska. Om du har svårt att förstå engelska kan du få svensk text genom att klicka på “YouTube” (i nedre högra hörnet) för att gå till YouTube där videon automatiskt startar. I YouTube klickar du på kugghjulsikonen, sedan klicka på “Subtitles”, klicka sedan på auto-translate och välj svenska. Detta fungerar någorlunda bra men det kan bli en del felaktigheter i översättningen).
Ett lågt p-värde indikerar att det observerade resultatet, eller ett mer extremt sådant, vore osannolikt under nollmodellen. Vi förkastar nollhypotesen till förmån för en alternativ hypotes, utan att detta innebär att alternativhypotesen har tilldelats en sannolikhet. Men exakt hur lågt måste p-värdet vara för att vi ska ta detta steg? Detta gränsvärde bör bestämmas från fall till fall och kallas för signifikansnivå, eller alfa.
Vi använder analytisk statistik för att beräkna ett p-värde. Nästa steg är att jämföra detta beräknade p-värde med vår förutbestämda signifikansnivå (alfa). Om p-värdet är lägre än alfa förkastar vi nollhypotesen och anser att den alternativa hypotesen är den mest sannolika. Om p-värdet omvänt är högre än alfa kan vi inte förkasta nollhypotesen; våra resultat ger inte tillräckligt med bevis för att motsäga den.
Av tradition sätts alfa oftast till ≤0,05. Därför skulle ett p-värde på 0,045 klassificeras som statistiskt signifikant, medan ett p-värde på 0,055 inte skulle göra det. Det är dock viktigt att komma ihåg att denna gräns på ≤0,05 inte är svartvit. I verkligheten är resultaten för p=0,045 och p=0,055 statistiskt sett väldigt lika. På grund av detta bör exakta p-värden alltid redovisas, istället för att bara ange om ett fynd var “signifikant” eller inte.
Sammanfattningsvis: Signifikansnivån (alfa) är en fast gräns som bestäms av forskaren, vanligtvis i förväg. Den beror inte på våra observationer och beräknas inte; det är snarare ett medvetet beslut baserat på den säkerhetsmarginal som behövs för att undvika att begå ett typ I-fel (ett falskt positivt resultat). P-värdet beräknas å andra sidan utifrån observerade data med hjälp av ett specificerat statistiskt test och modellantaganden.
Signifikansnivå och ren slump
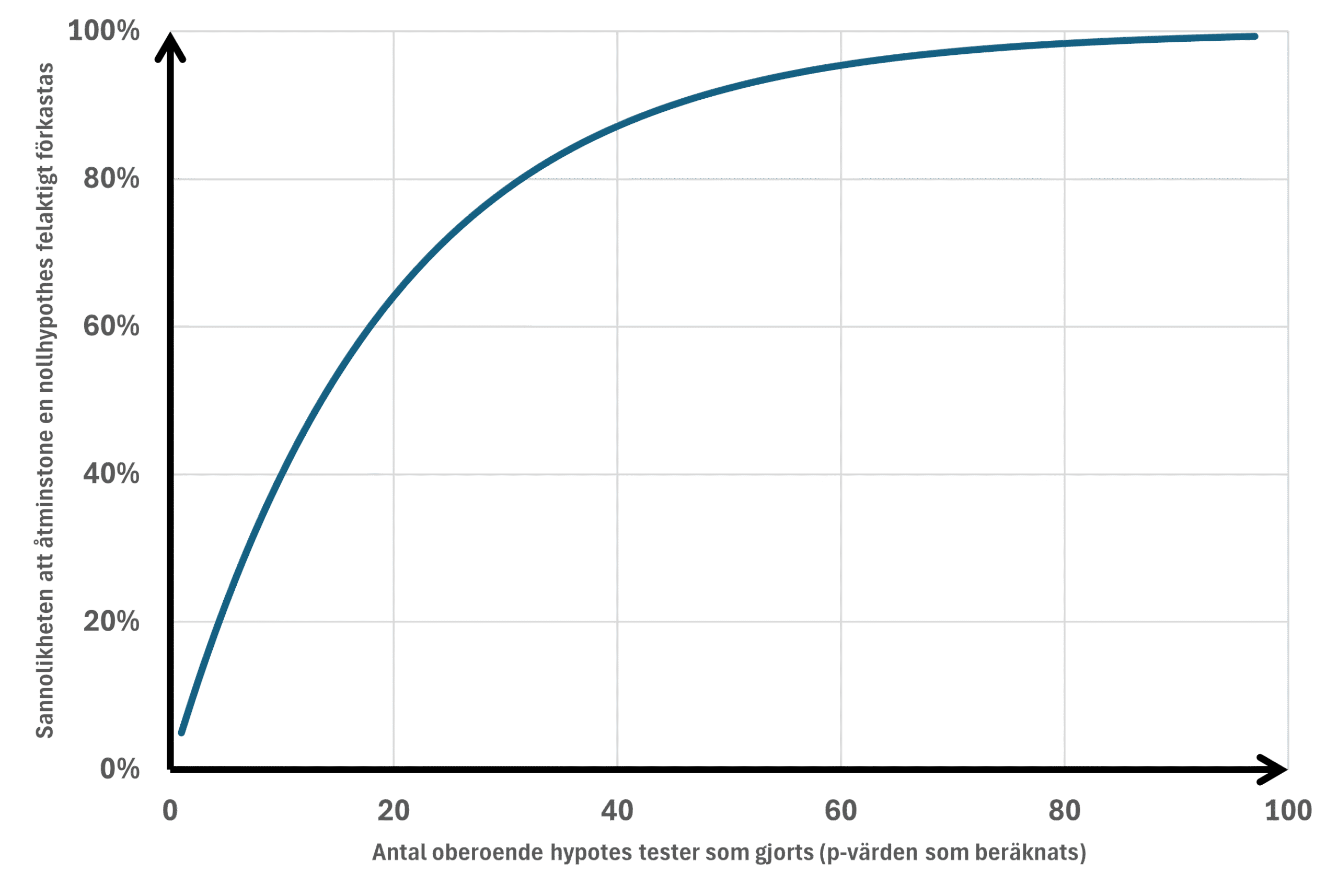
Anta att vi vill veta vilka variabler som skiljer sig åt mellan två grupper: de som har haft en sjukdom jämfört med de som inte har haft det (eller så kan det vara de som svarar ja på en fråga jämfört med de som svarar nej). Anta också att vi vill undersöka 50 olika variabler, varav vissa är kategoriska medan andra är kontinuerliga. Att använda chi-två-test eller t-test för att jämföra de två grupperna skulle resultera i 50 p-värden, vissa under och vissa över 0,05. Ett p-värde ≤0,05 kan dock uppstå av ren slump utan att det representerar en verklig skillnad mellan grupperna. Sannolikheten att felaktigt förkasta nollhypotesen (att tro att ett lågt p-värde representerar något annat än ren slump) ökar ju fler test vi gör (Figur 1).
Att bestämma signifikansnivån
När flera p-värden inom en definierad familj av p-värden presenteras bör vi överväga att justera gränsvärdet för signifikans eller på annat sätt kontrollera för multiplicitet. Detta är som viktigast när man gör konfirmerande påståenden, men bör även övervägas vid explorativ analys. Det finns olika metoder för att göra detta.
Family-Wise Error Rate (FWER) och False Discovery Rate (FDR)
Family-Wise Error Rate (FWER) är sannolikheten att begå minst ett typ I-fel – det vill säga minst ett falskt positivt resultat – över en samling statistiska tester. Enklare uttryckt: Om du utför flera hypotesprövningar är FWER risken att en eller flera av dem felaktigt framstår som statistiskt signifikanta av ren slump (Figur 1). Om “m” nollhypoteser är sanna och testerna är oberoende är chansen för åtminstone ett falskt positivt resultat: 1 – (1 – α)^m (där m = antalet statistiska tester). Till exempel, om vi gör 20 statistiska tester är risken att begå minst ett typ I-fel:
I det här exemplet skulle det vara 64 % risk att minst ett statistiskt test blir falskt positivt. FWER handlar om att kontrollera sannolikheten för att göra någon sådan falsk upptäckt i hela uppsättningen av tester. FWER är striktare än False Discovery Rate (FDR):
- FWER kontrollerar risken att få något falskt positivt resultat.
- FDR kontrollerar den förväntade andelen falska positiva resultat bland de statistiskt signifikanta fynden.
Översikt över “universella justerare” av signifikansnivån
| Metod | Beskrivning | Fördelar | Nackdelar |
|---|---|---|---|
| Bonferroni-metoden | Kontrollerar Family-Wise Error Rate (FWER). Håller risken att få ens ett enda falskt positivt resultat på din valda signifikansnivå eller lägre (exempelvis ≤5%). För justerade p-värden är Holm-Bonferroni vanligtvis att föredra framför omodifierad Bonferroni. | Mycket enkel att förstå. Kräver inte att varje test är oberoende. | “Mycket konservativ”, vilket gör det svårt att hitta statistisk signifikans om du beräknar många p-värden. |
| (Dunn-)Šidák’s korrektion | Kontrollerar Family-Wise Error Rate (FWER). Håller risken att få ens ett enda falskt positivt resultat på din valda signifikansnivå eller lägre (exempelvis ≤5%). Använd aldrig denna metod (det är bättre att använda någon av de rekommenderade metoderna nedan). | Något mindre konservativ än Bonferronimetoden. Skillnaden är dock mycket liten och denna metod kommer sannolikt, precis som Bonferronimetoden, att missa relevanta fynd. | Mindre enkel att förstå. Kräver dessutom att vart och ett av dina 20 tester är helt oberoende av de andra (vilket ofta inte är fallet i verkligheten).. |
| Holm-Bonferroni metoden | Kontrollerar Family-Wise Error Rate (FWER). Håller risken att få ens ett enda falskt positivt resultat på din valda signifikansnivå eller lägre (exempelvis ≤5%). Lämplig för konfirmerande forskning. | Mindre konservativ jämfört med Bonferronimetoden, vilket innebär att chansen att hitta en sann statistisk signifikans är högre än om du använder Bonferronimetoden. Kräver inte att varje test är oberoende. | Den är fortfarande relativt konservativ. Om du gör hundratals tester kommer den fortfarande att eliminera många potentiellt giltiga fynd. |
| Holm-Šidák’s korrektion | Kontrollerar Family-Wise Error Rate (FWER). Håller risken att få ens ett enda falskt positivt resultat på din valda signifikansnivå eller lägre (exempelvis ≤5%). Lämplig för konfirmerande forskning. | Mindre konservativ jämfört med Šidák’s korrektion, vilket innebär att chansen att hitta en sann statistisk signifikans är högre än om du använder Bonferronimetoden. Kräver att varje test är oberoende. | Största nackdelen är att de olika hypotestesterna måste vara helt oberoende av varandra. |
| Benjamini-Hochberg proceduren | Istället för att kontrollera risken för att få något falskt positivt resultat, kontrollerar denna metod False Discovery Rate (FDR). Det innebär att den accepterar en liten, känd andel falska positiva resultat i utbyte mot en mycket högre chans att upptäcka sanna signifikanta skillnader. Lämplig för explorativ forskning. | Betydligt mer statistisk styrka (power) än någon av metoderna ovan. Det är guldstandarden för explorativ dataanalys där du screenar dussintals eller hundratals variabler för att se vad som verkar lovande. Du använder BH när du vill kasta ut ett brett nät för att hitta uppslag för framtida, mer riktad forskning. Detta är det bästa tillvägagångssättet när man beräknar många p-värden (>20?). Kräver inte fullständigt oberoende under många vanliga förhållanden med positivt beroende (vid godtyckligt beroende kan dock Benjamini-Yekutieli eller andra metoder vara mer lämpliga). | Du kan få vissa falskt positiva fynd, men deras förväntade andel bland de förkastade hypoteserna är kontrollerad. |
Bonferroni-metoden
Denna enkla metod innebär att vi dividerar den önskade övergripande signifikansnivån (ofta 0,05) med antalet beräknade p-värden. I ett exempel med 50 beräknade p-värden innebär en Bonferroni-justering att endast p-värden ≤0,001 ska betraktas som statistiskt signifikanta, vilket kan vara svårt att uppnå. Därför är Bonferronimetoden inte lämplig om du beräknar många p-värden. För justerade p-värden är Holm-Bonferroni vanligtvis att föredra framför omodifierad Bonferroni eftersom den kontrollerar FWER och är mindre konservativ. Bonferroni är dock fortfarande användbar i vissa sammanhang, särskilt för samtidiga konfidensintervall (se nedan).
(Dunn-) Šidáks korrektion
Den vanliga Bonferroni-korrigeringen sätter gränsvärdet för alla tester till helt enkelt α/m. Šidák-korrigeringen använder en exakt formel: 1 – (1 – α)1/m. Eftersom 1 – (1 – α)1/m är något större än α/m är Šidáks gränsvärde lite mer förlåtande. Till exempel, med α = 0,05 och m = 10 tester blir signifikansnivån 0,005 för Bonferroni och 0,005116 för Šidák. Så Šidák är onekligen något mer kraftfull än vanlig Bonferroni.
Holm-Bonferroni använder inte bara ett enda gränsvärde; den anpassar sig dynamiskt (se nedan). Om vi ställer enstegsvarianten av Šidák mot flerstegsvarianten (step-down) av Holm-Bonferroni för 10 oberoende tester, händer följande: För det allra första (minsta) p-värdet vinner Šidák med en mikroskopisk marginal (0,005116 mot Holms 0,005000). För det andra p-värdet är Holms gränsvärde nu α/9 = 0,00555, vilket redan är högre (mer förlåtande) än Šidáks statiska 0,005116. För det tredje p-värdet hoppar Holms gränsvärde upp till α/8 = 0,00625, och slår därmed Šidák ytterligare. Eftersom Holms sekventiella gränsvärden snabbt blir mycket större än Šidáks enda fasta gränsvärde, kommer Holm-Bonferroni i allmänhet att korrekt förkasta fler nollhypoteser totalt sett.
Holm-Bonferroni metoden
Kontrollerar Family-Wise Error Rate (FWER) precis som den vanliga Bonferronimetoden, vilket innebär att den håller risken att få ens ett enda falskt positivt resultat på din valda signifikansnivå eller lägre (exempelvis ≤5%). Istället för att behandla varje test på samma sätt använder Holm-Bonferroni en “stegvis” (step-down) metod. Det är i grunden en smartare och mindre bestraffande version av standard-Bonferroni-korrektionen. Proceduren går till steg för steg:
- Rangordna dina p-värden: Sortera alla dina p-värden från det minsta (mest signifikanta) till det största (minst signifikanta).
- Tillämpa ett glidande gränsvärde: Istället för att dividera din alfa (exempelvis 0,05) med det totala antalet utförda tester för varje enskilt test, ändras gränsvärdet beroende på p-värdets rang. Formeln för det justerade gränsvärdet för det i:te rangordnade p-värdet är:
(Där alfa är 0,05, m är det totala antalet beräknade p-värden, och i är p-värdets rang). - Stegvis nedåt (The Step-Down): För ditt minsta p-värde är gränsvärdet exakt detsamma som det som räknas fram vid standard-Bonferroni. Om ditt p-värde är lika med eller under detta är det signifikant. För ditt näst minsta p-värde blir gränsvärdet något lättare att uppnå jämfört med det som Bonferronimetoden räknar fram. Du fortsätter sedan nedåt på listan. Gränsvärdet blir större (lättare att uppnå) jämfört med Bonferroni metodens framräknade gränsvärde för varje steg. Så fort du stöter på ett p-värde som är större än dess beräknade gränsvärde, stannar du. Den variabeln, och alla variabler efter den på listan, förklaras som statistiskt icke-signifikanta.
I en “Step-Down”-procedur som Holm-Bonferroni fungerar p-värdena som en serie grindar. För att nå den sista grinden måste du först ha tagit dig igenom alla föregående grindar. När kalkylatorn stöter på det första icke-signifikanta värdet så stänger den dörren helt. Enligt reglerna för Holm-Bonferroni deklareras då det p-värdet och alla efterföljande p-värden som icke-signifikanta – oavsett hur små de är i förhållande till sina egna teoretiska gränsvärden. Detta är själva “straffet” i Holm-Bonferroni: om en länk i kedjan brister, så faller resten av testerna med den för att skydda mot falska positiva resultat.
Holm-Bonferroni kalkylator
The Holm- Šidák korrektion
Om dina tester är strikt oberoende är Holm-Šidák ofta det bästa valet. Både Holm-Šidák och Holm-Bonferroni använder exakt samma “step-down”-algoritm (där p-värdena sorteras och gränsvärdet gradvis görs lättare att passera). Skillnaden ligger helt och hållet i den matematiska formeln de använder i varje steg:
Eftersom Šidák-formeln beräknar den exakta sannolikheten för oberoende händelser i stället för en approximation, är dess gränsvärde alltid något högre (mer förlåtande) i varje enskilt steg. Därför kommer Holm-Šidák alltid att ha lika hög eller högre statistisk styrka än Holm-Bonferroni.
(Kalkylator för Holm-Šidák kommer)
Benjamini-Hochberg proceduren
Kontrollerar den förväntade andelen False Discovery Rate (FDR). Detta är ett massivt skifte i statistisk filosofi. Istället för att försöka garantera noll falska positiva resultat accepterar BH-proceduren att falska positiva resultat kommer att inträffa. Dess mål är att kontrollera den förväntade procentuella andelen av dina “signifikanta” fynd som faktiskt är falska. Om du sätter FDR till 0,05 strävar metoden efter att hålla den förväntade andelen falska upptäckter bland de förkastade hypoteserna på eller under 5 %, givet dess antaganden. I en enskild studie kan den faktiska andelen vara högre eller lägre. Proceduren går till steg för steg:
- Rangordna dina p-värden: Sortera dem från det minsta överst till det största längst ner på listan.
- Beräkna ett kritiskt värde för varje p-värde: Gränsvärdet växer mycket snabbare än i Holm-Bonferronimetoden. Formeln är:
Kritiskt värde = (i / m) * Q
(Där i är rangen, m är det totala antalet beräknade p-värden, och Q är din valda False Discovery Rate, vanligtvis 0,05). - Stegvis uppåt (The Step-Up): Du tittar på din lista och hittar det största p-värdet som är mindre än dess motsvarande kritiska värde. Den variabeln, och alla variabler som är rangordnade under den (med ett mindre p-värde), förklaras som statistiskt signifikanta.
Step-up-proceduren kan vara lite svår att greppa, så låt oss titta på ett exempel. I kalkylatorn nedan, behåll alfa på 0.05 och mata in följande p-värden: 0.060, 0.039, 0.035, 0.015, 0.005. Så här ska varje p-värde rangordnas och jämföras med sitt motsvarande kritiska värde:
- Rang 1:
0.005(Kritiskt värde: 1/5 * 0.05 = 0.010) -> Godkänns (0.005 < 0.010) - Rang 2:
0.015(Kritiskt värde: 2/5 * 0.05 = 0.020) -> Godkänns (0.015 < 0.020) - Rang 3:
0.035(Kritiskt värde: 3/5 * 0.05 = 0.030) -> Underkänns (0.035 > 0.030) - Rang 4:
0.039(Kritiskt värde: 4/5 * 0.05 = 0.040) -> Godkänns (0.039 < 0.040) - Rang 5:
0.060(Kritiskt värde: 5/5 * 0.05 = 0.050) -> Underkänns (0.060 > 0.050)
Nu kommer det knepiga. Eftersom Benjamini-Hochberg är en step-up-procedur ska kalkylatorn börja i botten (Rang 5) och arbeta sig uppåt tills den hittar ett “Godkänns”. Eftersom Rang 4 godkänns måste allt från rang 1 till 4 förklaras signifikant, även om de underkänns när de jämförs med sina motsvarande kritiska värden. Följaktligen godkänns Rang 4 eftersom den klarade sitt eget kritiska värde, medan rang 1–3 förklaras godkända oavsett sina kritiska värden på grund av step-up-regeln.
Benjamini-Hochberg kalkylator
Tips om vilken justeringsmetod man bör använda
- Använd inte den vanliga Bonferroni-korrektionen eller (Dunn-) Šidáks korrektion om ditt syfte bara är att utvärdera multipla p-värden. De andra metoderna är alltid bättre om ditt mål är att maximera antalet upptäckta signifikanser och du bara bryr dig om p-värden. Men om du vill (eller krävs på att) redovisa konfidensintervall för dina data justerade för att du räknar fram flera konfidensintervall, är den klassiska Bonferroni-korrigeringen fortfarande ett mycket adekvat och motiverat val (se nedan).
- Att ha ett litet antal tester (som 5, 10 eller 15) innebär vanligtvis att du har specifika, förplanerade hypoteser. Du “fiskar” inte efter data; du försöker bekräfta specifika teorier. I dessa fall vill du ha ett strikt skydd mot falska positiva resultat, så Holm-Bonferroni eller Holm-Šidáks korrektion (som kontrollerar FWER) är det rätta valet. Använd Holm-Bonferroni eller Holm-Šidáks korrektion när du bedriver konfirmerande forskning. Om ett falskt positivt resultat skulle leda till att man ändrar en klinisk riktlinje, godkänner ett värdelöst läkemedel eller gör ett definitivt påstående i en tidskrift med hög impact, måste du använda Holm-Bonferroni eller Holm-Šidáks korrektion för att garantera att den sammanlagda risken för att få ett eller flera falskt positiva resultat begränsas till 5 %. Även om du har 30 p-värden måste du, om insatserna är höga, acceptera den minskade statistiska styrkan och använda Holm-Bonferronieller Holm-Šidáks korrektion.
- Använd Benjamini-Hochberg när du bedriver explorativ forskning. Om ditt mål helt enkelt är att hitta “variabler av intresse” för att testa dem igen i en framtida, mer riktad studie, är Benjamini-Hochberg perfekt. Du accepterar en False Discovery Rate på ≤5 % eftersom ett falskt positivt resultat här bara innebär ett visst slöseri med tid i nästa studie, inte ett katastrofalt fel i verkligheten. Du kan använda BH även om du bara har 12 p-värden, så länge ditt mål är rent explorativt. När du går över till 20, 50 eller 100+ p-värden går du vanligtvis in i området för explorativ forskning (t.ex. screening av dussintals gener, biomarkörer eller demografiska variabler). I explorativ forskning är Benjamini-Hochberg (som kontrollerar FDR) absolut det rätta valet eftersom du vill kasta ut ett brett nät och inte vill att ett strikt FWER-straff ska dölja värdefulla uppslag.
Om du utför 100 tester och använder Holm-Bonferroni med alfa = 0,05, är målet att du i 95 av 100 fall ska ha noll falskt positiva resultat. Om du å andra sidan använder Benjamini-Hochberg (FDR) på 5 %, accepterar du en metod som kontrollerar den förväntade andelen falska upptäckter bland de förkastade hypoteserna till att ligga på eller under 5 %, givet dess antaganden. I en enskild studie kan den faktiska andelen vara högre eller lägre. Skillnaden i stränghet mellan dessa båda metoder är därför enorm!
Scheffés metod och Tukeys HSD
Detta är metoder för uppföljande analyser (post hoc-tester) till en ANOVA. Om ANOVA-testet ger ett signifikant p-värde (vilket betyder att minst en grupp skiljer sig från de andra) gör man post hoc-tester för att ta reda på exakt var dessa skillnader finns. Du kan göra alla möjliga parvisa jämförelser (t.ex. Grupp A mot Grupp B) med hjälp av Tukeys metod. Om du har olika stora stickprov i grupperna måste du dock använda Tukey-Kramer-justeringen. Om du i stället vill testa mer komplexa kombinationer av grupper (t.ex. Grupp A mot en sammanslagning av Grupp B och C) använder du Scheffés metod. Dessa tillvägagångssätt är skräddarsydda för gruppjämförelser i en ANOVA och bygger på specifika testfördelningar, vilket innebär att de inte fungerar som “universella justerare” av signifikansnivån på samma sätt som en Bonferroni-korrigering.
Upprepad testning över tid av samma utfall
Medan Holm-Bonferroni och Benjamini-Hochberg är dina standardmetoder för att testa dussintals variabler samtidigt i slutet av en studie, är O’Brien-Fleming-gränsen eller Pocock-gränsen metoder för att testa en enda primärvariabel vid olika tidpunkter medan en studie fortfarande pågår. Det typiska exemplet är interimsanalyser av interventionsstudier. Interimsanalyser skapar exakt samma problem med Family-Wise Error Rate (FWER) som vi diskuterade tidigare. Om du testar dina data på en 0,05-signifikansnivå år 1, år 2, år 3, år 4 och år 5, ökar din totala risk för ett falskt positivt resultat till omkring 14 %. Du “fiskar” i praktiken efter ett signifikant resultat genom att kontrollera data upprepade gånger. För att hålla den totala felmarginalen på 5 % måste du “spendera” ditt alfa (din signifikansnivå på 0,05) försiktigt över dessa olika kontroller.
Pocock-gränsen sänker signifikansnivån och håller den konstant under studien. Samma signifikansnivå tillämpas vid varje interimsanalys. Om data till exempel analyseras fyra gånger (vid 25 %, 50 %, 75 % och 100 % av insamlade observationer) sätts signifikansnivån till 0.0182.
O’Brien-Fleming-gränsen, eller en alfa-förbrukningsmetod av O’Brien-Fleming-typ, tilldelar väldigt lite alfa tidigt och lämnar det slutgiltiga gränsvärdet nära den konventionella nivån.. Den dikterar exakt vad ditt p-värdes-tröskelvärde måste vara vid varje interimskontroll. Dess främsta kännetecken är att den gör det otroligt svårt att avbryta en studie i förtid, men den lämnar det slutliga tröskelvärdet nästan helt oförändrat. Om du planerar 4 kontroller av data (3 interimsanalyser och 1 slutanalys), ser O’Brien-Flemings p-värdesgränser ungefär ut så här:
- Koll 1 (25 % av data): p-värdet måste vara ≤ 0,00005 för att avbryta i förtid.
- Koll 2 (50 % av data): p-värdet måste vara ≤ 0,0039för att avbryta i förtid.
- Koll 3 (75 % av data): p-värdet måste vara ≤ 0,0184 för att avbryta i förtid.
- Slutlig koll (100 % av data): p-värdet måste vara ≤ 0,0412 för slutlig signifikans. (Notera hur det slutliga p-värdet är 0,0412, vilket ligger mycket nära standardnivån 0,05!)
O’Brien-Fleming-metoden bevarar det slutliga p-värdet. Eftersom du “spenderar” väldigt lite av ditt alfa under de tidiga kontrollerna, ligger ditt tröskelvärde vid studiens slut fortfarande mycket nära 0,05. Dessutom förhindrar O’Brien-Fleming-metoden att studien avbryts i förtid. Tidigt i en studie kan data vara mycket instabila. Några tursamma framgångar kan få ett läkemedel att framstå som ett mirakelmedel. Det massiva hindret vid den första kollen (t.ex. p ≤ 0,00005) säkerställer att du bara avbryter studien i förtid om bevisen är absolut överväldigande. O’Brien-Fleming-gränsen bör vara din föredragna standardmetod för att testa en enskild primärvariabel vid olika tidpunkter medan en studie fortfarande pågår.
I vilket sammanhang bör jag justera signifikansnivån?
Signifikansnivån behöver sänkas om du presenterar flera p-värden. Men behöver jag ta hänsyn till alla p-värden som presenteras i en enskild tabell, alla p-värden i ett helt manuskript eller alla p-värden jag någonsin har beräknat i hela mitt liv? Om det sistnämnda vore sant skulle det innebära att alla erfarna statistiker skulle bli arbetslösa på grund av behovet av massiva justeringar av signifikansnivån.
Det är rimligt att justera för alla p-värden i ett manuskript som betraktas som faktiska resultat. P-värden beräknas ibland i korrelationer eller enkla regressioner enbart som en sorteringsmekanism för att avgöra vilka variabler som ska inkluderas i en slutgiltig multivariabel regression; dessa preliminära p-värden bör inte betraktas som resultat. Ett rimligt förslag kan vara att endast justera signifikansnivån för primära utfallsvariabler, en ståndpunkt som presenteras av Steve Grambow i denna video:
(Nedanstående video är på engelska. Om du har svårt att förstå engelska kan du få svensk text genom att klicka på “YouTube” (i nedre högra hörnet) för att gå till YouTube där videon automatiskt startar. I YouTube klickar du på kugghjulsikonen, sedan klicka på “Subtitles”, klicka sedan på auto-translate och välj svenska. Detta fungerar någorlunda bra men det kan bli en del felaktigheter i översättningen).
Konfidensintervall
Inom god vetenskaplig praxis (och hos många tunga tidskrifter) anses det ofta otillräckligt att bara redovisa p-värden. Man vill veta hur stor skillnaden är (effektstorleken), och redovisar därför konfidensintervall. Ofta redovisas ojusterade konfidensintervall när man räknar fram flera konfidensintervall. Om tidskriften kräver att du justerar dina konfidensintervall när du har räknat fram flera konfidensintervall så är det här den klassiska Bonferroni-metoden (som är en single-step-procedur) glänser.
Du kan extremt enkelt skapa samtidiga konfidensintervall för alla dina jämförelser med Bonferroni’s metod. Om du gör 5 tester med en önskad felmarginal på 5% (α = 0.05), delar du bara detta med 5. Ditt nya alfa för varje intervall blir 0.01. Du räknar sedan helt enkelt ut ett 99% konfidensintervall (1 – 0.01) för varje enskilt test.
Holm-Bonferroni är en flerstegsmetod (step-down). Den rangordnar dina p-värden och justerar gränsvärdena dynamiskt beroende på hur många tester som redan har passerat. Detta fungerar utmärkt för p-värden, men det är matematiskt mer komplicerat att översätta dessa dynamiska gränsvärden till justerade konfidensintervall. Samtidiga konfidensintervall som är kompatibla med Holm-Bonferroni är fullt möjliga, men de är mer omständliga och kan kräva specialiserad programvara.