We will experience brief service disruptions (see "Updates")
(the number of current visitors is automatically updated every 4 minutes)

Cite this page as:
-
Rating scales and their statistics
-
First published:
on:
Last updated:
If you want to share information about this web page...
The statistics behind rating scales might seem complicated at first. Once you’ve read through this webpage a couple of times, you’ll realize that the hard part isn’t finding the right rule (because one doesn’t exist), but rather finding a reasonable approach that fits your needs, and then finding the arguments to defend what you do.
You will understand this webpage best if you first read the pages Introduction to statistics, Observations and Variables, and Choosing statistical analysis.”
Introduction to Rating Scales
Dr. Citrus works at a healthcare center. His real name is actually something else, but due to his great interest in Vitamin C, both the staff and his patients call him Dr. Citrus. He has had several patients tell him that they felt better after starting to take Vitamin C. Now, Dr. Citrus wants to scientifically investigate whether people feel they achieve better health and quality of life if they start taking Vitamin C. In this study, he is more interested in people’s subjective experiences than whether actual changes can be seen in blood pressure, cholesterol, etc. Dr. Citrus chooses to measure perceived health using a questionnaire consisting of one or more questions. How should he go about this in practice? Let’s return to Dr. Citrus and his project in a moment.
Questionnaires can have open-ended questions where the respondent can answer freely. The alternative to open-ended questions is closed-ended questions with predefined response options. There are two variations here. One consists of response options without any inherent order, and the results are then measured on a nominal scale. The second alternative is, consequently, response options with an inherent order, and these are measured on an ordinal scale. The latter involves some form of grading and is generally referred to as a rating scale. The rest of this webpage will only discuss rating scales.
Can attitudes, emotions, and experiences be converted into numbers?
When measuring and analyzing emotions and experiences using quantitative methods (with numbers), one employs a philosophy of science approach known as positivism. Criticism can be directed at converting phenomena that are not governed by strict laws—such as emotions and perceptions—into numbers and statistics (feel free to follow the previous link and read the page on the philosophy of science). This is very much an ongoing debate, and it is wise to be aware of it.
Using Rating Scales
Questionnaires that attempt to quantify experiences, opinions, subjective health status, etc., with numbers use various forms of rating scales. Before running statistics on rating scales, there are several important choices that must be made:
- Determine what you want to measure (for example, perceived health).
- What is the purpose? Do you want to be able to distinguish between individuals (who think/experience differently), make predictions/prognoses (for example, regarding future needs for sick leave), or assess change over time? Here, you must decide, among other things, whether you want to measure once or look at the change between two measurements.
- Is there an existing instrument or questionnaire you can use? If not, you must first construct the instrument/questionnaire yourself and verify that it measures what you think it measures. If you are going to design your own instrument/questionnaire, the first step is to perform an operationalization. In this phase, you decide how the questions and response options will be structured.
- Determine how the collected data will be processed. Which statistical method should be used? This is largely determined by the choices you made during the operationalization.
Operationalization
Should the phenomenon be measured with a single question or with a questionnaire containing multiple questions? The advantage of a single question is that the subsequent data processing becomes much simpler. The advantages of using multiple questions for the same phenomenon are:
- Increasing the coverage: Different individuals do not experience a phenomenon in the same way, which makes it difficult to describe the phenomenon with just one question.
- Capturing nuances: It allows you to include different qualities or aspects of the phenomenon.
- Pinpointing changes: It helps identify exactly which part of the phenomenon is showing deficiencies, improvement, or deterioration.
Choosing a Scale Type
There are essentially three different types of scales:
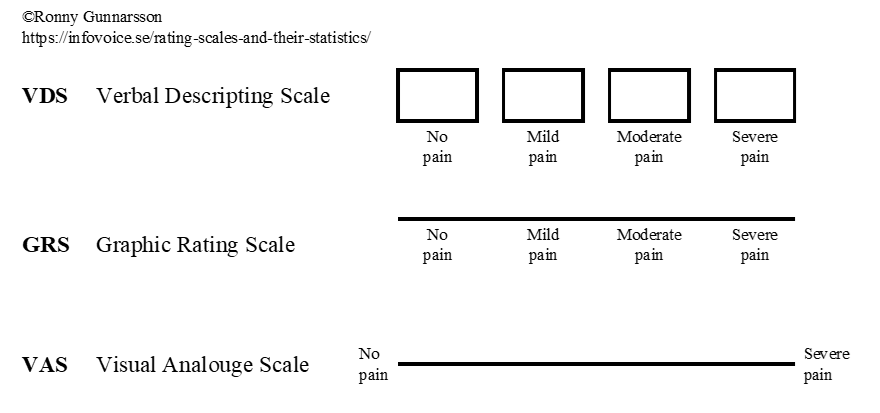
It may be the case that VDS possesses somewhat better test-retest reliability than GRS and VAS, making it the preferred choice.
The Likert Scale
A special type of verbal descriptive scale is the Likert scale. You present a statement, and the response options range from “strongly disagree” to “strongly agree,” with a few options in between. The Likert scale can have 3–7 options, though 4–5 is the most common.
Choosing Labels for the Response Options
VDS and GRS therefore have fixed scale steps. There is no strict rule for how many scale steps you should have, but each step must be given its own meaningful description, which likely becomes difficult if you exceed 6–7 steps. VAS has no fixed scale steps. When using VDS or GRS, it is generally recommended to avoid a midpoint for attitude questions; otherwise, having a midpoint is useful. When registering the responses, for example in a computer program, the answer must be coded into a value or label. Sometimes (with VDS or GRS), this label is already printed on the form that the individual/patient fills out. Examples of labels for different response options:
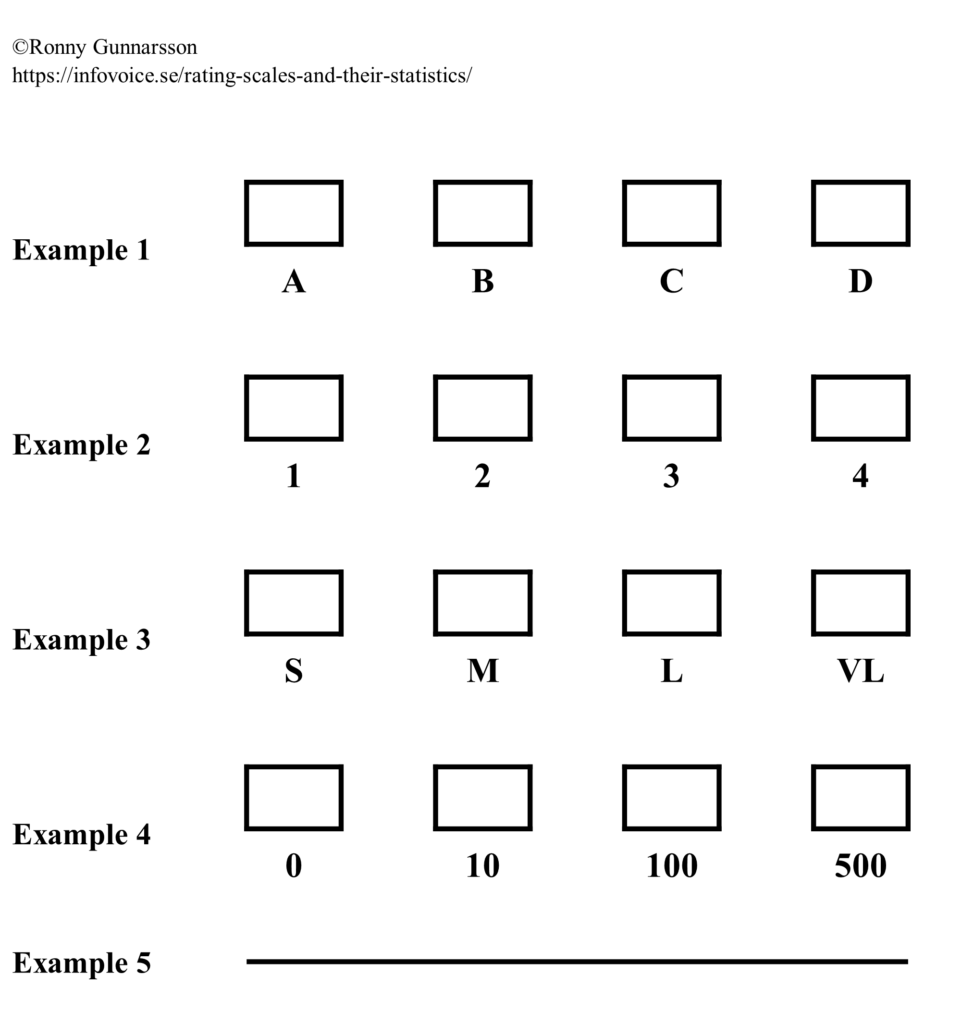
Examples 1, 3, 4, and 5 are all response alternatives with examples of symbols representing an ordered structure without other mathematical properties (= ordered qualitative variable). In example no. 4, 100 is therefore simply more than 10, but not necessarily exactly 10 times as much. Example no. 2 could theoretically be either an ordered qualitative or a discrete quantitative variable. An example of the latter could be: “How many visits to the healthcare center have you made in the last quarter?”
Dr. Citrus’s Operationalization
Dr. Citrus has now decided to randomize the patients into two groups: Vitamin C or placebo. He plans to give them a questionnaire with a few questions about their health. The patients will answer this questionnaire both at the beginning of the study and after 6 months. He decides that all the questions will be in the form of various statements that they must respond to by checking one of several fixed options, a so-called Likert scale using VDS (see above). (A proper operationalization should, of course, describe the questions and response options in detail, but we will skip that here for Dr. Citrus’s example).
Measuring and Reporting Change with Rating Scales
Returning to our introductory example, Dr. Citrus wanted to measure change. Dr. Citrus then has three options: transition questions, marginal models, and cross-tabulations. The latter is the only option that provides a measure (usually a p-value) of the degree of uncertainty when claiming that a change has actually occurred. There is no rule stating that one method is better than the other. Let’s take a closer look at these three options:
Transition Questions
At the end of the study period, questions are asked about what change the individual has experienced. An example of this could be a question found in the SF-36 questionnaire: “Compared to one year ago, how would you rate your health in general now?” The response alternatives are:
If you use transition questions, there is no immediate need to ask questions at the beginning of the study. (However, you might still want initial questions to be able to describe who was included and how they felt at the time). If a transition question is used at follow-up, there is no reason to calculate a difference between the baseline and the follow-up.
Marginal Models
Here, changes over time are displayed graphically. There are different ways to do this. One example is through stacked fractional bar charts:
Cross-tabulations
Here, a measure (usually a p-value) is calculated to determine whether the change falls within the margin of random error or not. There are three fundamentally different situations for this type of analysis:
- Seeing if the change in a single group is statistically significant compared to a fixed reference value, which is usually zero (no change)
- Seeing if the difference in change between two matched groups is statistically significant.
- Seeing if the difference in change between two unmatched groups is statistically significant.
Further down, a more detailed description is provided on how to calculate various measures (usually p-values) in this type of comparative analysis.
Analytical Statistics and Rating Scales
Let’s assume that Dr. Citrus finds evidence that Vitamin C lowers blood pressure. Naturally, it is important for the overall effect that the patient receives good, positive information about Vitamin C. He then starts a new study where he wants to find out how patients perceive this information. He provides the information to the patients individually, one-on-one. Immediately after the session, patients and Dr. Citrus each answer a single question:
- Question to be answered by the patient: “I feel that the information about Vitamin C made me positively inclined to take the tablet (check the option that fits best).”
- Question answered by DR. Citrus: “I believe that this patient felt the information about Vitamin C made him/her positively inclined to take the tablet (check the option that fits best).”
Both questions were Likert scales with the following options: Strongly agree, Somewhat agree, Somewhat disagree and Strongly disagree.
From this simple survey, Dr. Citrus asks a few questions:
- Did men and women perceive the meeting with the doctor differently? This is a group comparison of unmatched groups. The groups are unmatched because the men and women did not meet the doctor at the same time, but rather had their own individual appointments.
- Is there a relationship between men’s and women’s perceptions of meeting the doctor? This is an analysis of association, which is the flip side of the coin compared to the group comparison above. Group comparisons and analysis of association are therefore related in a way, and it can be shown that group comparisons are merely a special case of analysis of association.
- Is there a relationship between the patient’s and the doctor’s perception of what happened during the meeting? This is an analysis of agreements.
In the first question, Dr. Citrus wants to know if men and women perceived the situation differently. The answers to the question posed to the patients are then analyzed, and he compares the responses from the men and the women. These are unmatched groups because the men and women participated in their own separate doctor’s appointments. There are two options: the data can either be analyzed using the Mann-Whitney U test (if we take into account that the response options have an inherent order—an ordinal scale), or with a Chi-square test (if we choose to ignore that the response options have an inherent order, thus treating the data as nominal data). As a rule, it is better to treat this as ordinal data and use the Mann-Whitney U test.
In the second question, we want to see if there is a relationship between the perceptions of female and male patients. Analysis of association examines how two measurements of different phenomena (different consultations) covary. It is therefore reasonable to use rank correlation (if we take into account that the response options have an inherent order—an ordinal scale) or Cramer’s V if we disregard the fact that the response options have an order. As a general rule, rank correlation would be the better alternative since an inherent order does exist.
In the third question, Dr. Citrus wants to know if there is a relationship between the patient’s opinion and his own perception of how the patient reacted. It is important to realize that there are different types of relationships. The relationship between the patients’ rating and his own rating is the degree of agreement (similarity) between different assessments of the exact same situation (the same meeting between patient and doctor). In this case, a weighted kappa coefficient is appropriate (if we take into account that the response options have an inherent order—an ordinal scale) or a standard kappa coefficient (if we choose to ignore the inherent order, thus treating the data as nominal).
Paradigm Conflict! What should I do?
You should use a measurement scale (and corresponding statistical methods) that fits the type of variable. The variable’s level of measurement (which measurement scale is appropriate) therefore dictates your choice of which type of statistics to use. (Feel free to read our page on Observations and Variables, which explains this further). However, there are differing opinions specifically regarding rating scales and which mathematical measurement scale should be used. These different views can be grouped into three main approaches:
- Some suggest treating rating scales just like any standard numbers, meaning the scale steps are considered equidistant (equal in size). This view used to be completely dominant but has become less common today, especially in Scandinavian countries. However, quite a few statisticians still argue that this is the correct approach. When it comes to the VAS, for example, the reasoning is that during the statistical analysis, you are not actually analyzing pain, but rather millimeters on a piece of paper. In that context, 80 mm on the paper is exactly twice as much as 40 mm. It is only after the p-value has been calculated and needs to be interpreted or discussed that you take into account that those millimeters represent something else, such as perceived pain.
- The second main approach is to treat rating scales as ordinal data and strictly use non-parametric statistical methods. However, this approach is not entirely consistent when evaluating changes over time. Here, they allow for calculating a difference between an initial baseline and a follow-up measurement. Proponents argue that this is the most practical way to differentiate a large change from a small one.
- The final approach is the most consistent and strict from a mathematical perspective. In principle, all rating scales are categorical (= qualitative) variables measured on an ordinal scale. This means that an 8 is more than a 4, but since the exact distance between the scale steps is undefined, we cannot confidently say that 8 is exactly twice as much as 4. A direct consequence of this is that you are not allowed to calculate sum scores, means, or differences. This last restriction severely complicates matters if you want to look at changes over time using a rating scale like the VAS. You simply cannot take a final value minus an initial value and use the raw difference if the variable is qualitative and measured on an ordinal scale. One workaround that is considered permissible is to calculate a difference and then transform those differences into categories like “improved,” “unchanged,” or “worse.” You can let “improved” be denoted by +1, “unchanged” by 0, and “worse” by -1. The changes are thereby transformed into a brand new ordinal scale with three distinct, ordered steps. Naturally, during this transformation, information regarding the exact magnitude of the change is lost.
Main approach C is the most theoretically appealing, which strongly speaks in its favor. Approach A can, to some extent, defend its position theoretically. Furthermore, approach A seems to be widely used in international scientific publications (especially outside the Nordic countries), and some peer reviewers (who will evaluate your submitted article) may be entirely unfamiliar with approach C. Approach B is a compromise that fundamentally lacks a theoretical foundation and, moreover, seems to have only moderate support among reviewers (in my own experience). How “purist” should you be (option C), and is having a good manuscript rejected an acceptable price to pay for that purity? There are no definitive answers here; it is important that you think this through yourself and make a choice.
A pragmatic compromise is to report p-values calculated according to all three main approaches, and then let the reader decide. By doing this, you show the consequences of the different methodological choices outlined above. Examples of publications where this practical compromise has been used:
- Rosenfeld et al. write (translated): “There is no international consensus in this matter; therefore, changes in VAS are analyzed using the parametric ANOVA and the nonparametric Friedmann’s test applied to both raw and transformed differences, although the authors prefer the latter.“
This article is an example of how one can compare the change in pain (measured with VAS) between unmatched groups by presenting the results of calculations according to the three main approaches A–C described above.
You can then see in the first row of Table 4 that the authors report the p-value for the difference between groups regarding the change in pain, rated with VAS, in three ways according to A, B, and C above. All calculations show a p-value <0.05, indicating that in this particular study, approximately the same result is obtained regardless of the calculation method, which is a strength. - Rembeck et al. write (translated): “Because there is no international consensus on how to compare changes in ordinal scales between groups we used both the parametric Student t test and the nonparametric Mann–Whitney test applied to both raw and transformed differences, although the authors prefer the latter.“
This article is an example of how one can compare the change in an attitude (measured with a questionnaire consisting of several questions) between two independent groups by presenting the results of calculations according to the three main approaches A–C described above. First, measures of the various dimensions and a total score were calculated according to the questionnaire instrument’s manual. This was done according to main approach A. Subsequently, the change measures were processed according to main approaches A–C described above. This method of handling data is therefore not theoretically consistent, because the authors chose to follow the manual for the questionnaire instrument even though the manual is based on main approach A.
You can then see that all p-values in Tables 1–3 indicate the p-value for the difference in change between the groups, calculated in three ways according to A, B, and C above. - Nordeman et al. write (translated): “Because there is no international consensus on how to compare changes in ordinal scales between groups, both the parametric t-test and the nonparametric Mann-Whitney test applied to both raw and transformed differences were used, although the authors prefer the latter.”
You can then see that all p-values in Tables 2–3 indicate the p-value for the difference in change between the groups, calculated in three ways according to A, B, and C above. - Rindner et al. write (translated): “However, there are different opinions between statisticians on how to treat observations measured by an ordinal scale. Some statisticians recommend using parametric methods such as t-test if observations are normally distributed. Others states that ordinal data must always be analysed using non-parametric methods such as Mann-Whitney’s test. A few statisticians also states that lack of equidistant scale steps as in ordinal data violates the assumptions for simple subtractions and consequently a change over time can’t be calculated. Hence, we have three possible approaches to analyse data that are all supported by statisticians but will result in different outcomes. To ensure that this choice does not lead to the wrong conclusions we analysed data using all three methods, an approach that has beenused previously“.
You can then see that all p-values in Table 2 indicate the p-value for the difference between the groups, calculated in three ways according to A, B, and C above.
Sum Scores?
Many questionnaires contain individual items (sub-questions) that are subsequently summed up to provide either a measure of a broader dimension or a total score. For example, the SF-36 questionnaire consists of 36 questions that can be aggregated into 8 “dimensions” (aspects) of health, as well as two summary component scores (PCS and MCS) that provide comprehensive measures of perceived physical and mental health, respectively. In principle, you can perform statistical calculations on the individual questions, the specific dimensions, or the combined total scores for the PCS and MCS. How do you construct these dimensions and summary scores based on the responses to the individual questions? Opinions differ on this matter. Let’s once again look at this through the lens of the three main approaches mentioned above:
- The rating scales are treated just like any standard numbers, i.e., the scale steps are considered equidistant (equal in size). This perspective is still the most common in scientific publications. The manuals for various questionnaires (such as the SF-36) are usually built on this way of viewing the survey responses. Sum scores are therefore typically calculated by simply adding up the answers from individual items. The theories behind why one considers it acceptable to sum up individual items are rarely discussed.
- Here, there is no real solution to the sum score dilemma. Because main approach B strives to emulate approach C without breaking too much with tradition, researchers often just do whatever the questionnaire instrument’s manual says. Most of the time, this means that when calculating dimensions and global measures, they end up following main approach A.
- Since all rating scales are considered ordinal data without equidistant scale steps (8 is more than 4, but not necessarily twice as much), you are not allowed to calculate sum scores, means, or differences. Therefore, a measure of an overarching dimension (aspect) is calculated in ways other than simply summing up individual responses (more on this below). The theories behind why calculations are done in a specific way are often presented.
Let’s take a closer look at main approach C. Below, Svensson describes a few different situations and possible solutions that follow approach C when you want to combine the responses from several questions into an overarching dimension:
| Situation / problem | Proposed solution | Example |
|---|---|---|
| Several similar questions that can be considered of equal value. The questions share the same ordinal scale, and it has more than two response alternatives. | Instead of a sum score, the median of the outcomes of several questions is used to represent a dimension . This provides a measure for the dimension without having to sum individual questions. | The SF-36 version 1 dimension Mental Health (questions 9b-9d, 9f, and 9h). |
| Several similar questions that can be considered of equal value. The questions have yes/no as response alternatives. | The number of yes (or number of no) answers classifies the individual into A, B, etc. . This provides a measure for the dimension without having to sum individual questions. | a) The SF-36 dimension Role Physical (questions 4a-4d). The individual is classified into A or B. b) The SF-36 dimension Social Functioning (questions 6 and 10). The individual is classified into A-E. |
| Two different, not directly equivalent questions that together are meant to reflect a single dimension. | Instead of a sum score, a cross-table is created where the possible response alternatives for one question form the columns, and the possible response alternatives for the other question form the rows . An evaluation of the possible combinations is then assigned to the different cells. | a) The SF-36 dimension Bodily Pain (questions 7 and 8), which can be graded A-G. b) The SF-36 dimension Social Functioning (questions 6 and 10), which can be graded A-F. |
| Several questions that reflect a progression (hierarchy). | The questions can be ordered according to the degree of what each question aims to describe, such as physical function. The first question where a physical limitation is reported becomes the value for the overarching dimension . | The SF-36 dimension Physical Functioning (questions 3a-3j). |
The table above is easier to understand if you read Svensson’s article . Main approach C does not calculate a total sum score (global health) for the SF-36. It is difficult to argue that the eight different dimensions in the SF-36 are strictly equivalent, and therefore, there is no solid basis for using the median across them as a measure of global health. On the other hand, you can calculate a global measure for the EuroQoL questionnaire—which only consists of 5 questions and two dimensions—and still remain faithful to approach C . The reason for this is that having only two dimensions allows them to be treated in the exact same way as when calculating the Bodily Pain dimension in the SF-36 using a cross-table (see the table above).
Choosing a Statistical Method for Rating Scales
Based on your perspective of what the rating scales actually represent, you then proceed with the appropriate statistical method (see the table below). This requires a bit of thought. The following section describes possible strategies depending on what you are trying to find out, and whether you want to apply main approach A, B, or C. It should be emphasized that opinions may differ regarding the recommendations below, and the author does not claim to hold the absolute truth on this matter.
| Main approach A | Main approach B | Main approach C | |
|---|---|---|---|
| Group comparison: Comparing a single measurement between two unmatched groups | Compare the groups using a parametric test (e.g., Student’s t-test for two unmatched groups) | Compare the groups using a non-parametric test (e.g., Mann-Whitney U test = Rank sum test = Wilcoxon rank-sum test) | Compare the groups using a non-parametric test (e.g., Mann-Whitney U test = Rank sum test = Wilcoxon rank-sum test) |
| Group comparison: Comparing a single measurement between two matched groups | Calculate the difference between the two individuals within the pair. Use a parametric test (e.g., Student’s t-test for matched/paired groups) to see if the mean of the differences within the pair differs statistically significantly from 0. | Calculate the difference between the two individuals within the pair. Use a non-parametric test (e.g., Wilcoxon signed-rank test) to see if the differences within the pair differ statistically significantly from 0. | Determine a difference within the pairs. Code the difference in each pair so that you get three alternatives: changed in one direction (the individual in group A improves more than the individual in group B), changed in the other direction (B improves more than A), and unchanged (no difference within the pair). Use a non-parametric test (Sign test) to see if the number where A>B differs statistically significantly from the number where A<B. … … or … … Use a method developed by Professor Elisabeth Svensson and further described and exemplified by Sonn & Svensson . |
| Group comparison: Comparing change in one group. Possibly against a fixed (expected) value. The expected value is often set to 0 (=no change). | Calculate the difference. Use a parametric test (e.g., One-sample Student’s t-test) to see if the mean of the difference differs statistically significantly from 0. | If the expected value is 0, the following is suggested: Calculate the difference. Use a non-parametric test (e.g., Wilcoxon signed-rank test) to see if the differences differ statistically significantly from the expected value. | If the expected value is 0, the following is suggested: Calculate the difference between measurement 1 and 2 for each individual. Recode the differences to changed in one direction (improved?), changed in the other direction (worsened?), and unchanged, respectively. Use a non-parametric test (Sign test) on the recoded differences to see if the number of individuals who improved differs statistically significantly from the number who worsened. … … or … … Use a method developed by Professor Elisabeth Svensson and further described and exemplified by Sonn & Svensson . |
| Group comparison: Comparing change between two unmatched groups | Calculate the difference for each individual. Use a parametric test (e.g., Student’s t-test for two unmatched groups) to see if the mean of the differences differs statistically significantly between the groups. | Calculate the difference. Use a non-parametric test on the differences (e.g., Mann-Whitney U test = Rank sum test = Wilcoxon rank-sum test) to see if the change in the groups differs. | Calculate the difference between measurement 1 and 2 for each individual. Recode the differences to changed in one direction (improved?), changed in the other direction (worsened?), and unchanged, respectively. Preferably, code improved as +1, unchanged as 0, and worsened as -1. Use a non-parametric test (e.g., Mann-Whitney U test = Rank sum test = Wilcoxon rank-sum test) on the recoded differences. |
| Group comparison: Comparing change between two matched groups | Calculate the difference for each individual. Then calculate the difference between the two changes within the pair. Use a parametric test (e.g., Student’s t-test for matched groups) to see if the mean of the differences within the pair differs statistically significantly from 0. | Calculate the difference for each individual. Then calculate the difference between the two changes within the pair. Use a non-parametric test (e.g., Wilcoxon signed-rank test) to see if the differences within the pair differ statistically significantly from 0. | Calculate the difference for each individual. Recode the differences to changed in one direction (improved?), changed in the other direction (worsened?), and unchanged, respectively. Preferably, code improved as +1, unchanged as 0, and worsened as -1. Now, determine a difference within the pairs (see below). Code the difference in each pair so that you get three alternatives: changed in one direction (the individual in group A improves more than the individual in group B), changed in the other direction (B improves more than A), and unchanged (no difference within the pair). Use a non-parametric test (Sign test) on the differences to see if the number of pairs where A improves more than B differs statistically significantly from the number where B improves more than A. |
| Analysis of covariation: Covariation between two assessments (made with rating scales) of different things | Compare the response outcome between the two assessments using Pearson’s correlation coefficient. | Compare the response outcome between the two assessments using Spearman’s rank correlation coefficient. | ? |
| Analysis of similarity: Showing similarity between two assessments (made with rating scales) of the same thing. | Here, most statisticians would probably choose the Kappa coefficient to compare the outcome between the two assessments. A few might choose Intra-Class Correlation (=ICC). | Compare the outcome between the two assessments using the Kappa coefficient. | Compare the outcome between the two assessments using the Kappa coefficient. … … or … … Use a method developed by Professor Elisabeth Svensson and further described and exemplified by Sonn & Svensson . |
As mentioned in the right-hand column above, Professor Elisabeth Svensson has developed a method for analyzing paired ordinal data (the Svensson rank-invariant method for paired ordinal data) . In the situation where we want to study change in a single group over time, there are two alternatives according to main approach C. One is the sign test and the other is the “Svensson method”. The differences between these two methods can be described as follows:
| Sign test | “The Svensson rank-invariant method for paired ordinal data” | |
|---|---|---|
| Takes the magnitude of the change into account | No, i.e., some collected information is ignored. | Yes, i.e., the information can be utilized better. |
| Provides a measure of the group’s change | Yes, in the form of a p-value. | Yes, in the form of an RP value that can vary between -1 and +1. If RP is 0, no change has occurred. (RP = Relative Position). |
| Provides a measure of the individuals’ dispersion from the group’s change | No. | Yes, in the form of an RV value that can vary between 0 and 1. A low value indicates that the individuals’ changes do not deviate much from the group trend. (RV = Relative rank-Variance). |
| Example where 371 patients are assessed with the “ADL staircase” multiple times over a number of years. In an analysis looking at the change over a 6-year period, it emerges that: 115 have deteriorated in ADL function, 250 are unchanged, and 6 have improved – Figure 2a in Sonn and Svensson’s article from 1997 . | The number of patients who have deteriorated is greater than the number who have improved (p<0.0000001). | RP=0.061 (with a standard error of 0.015) RV=0.0021 (with a standard error of 0.00085) |
| Likelihood that a reviewer / referee at a scientific journal understands the analysis method | Very high, as the sign test is already well known. | Low likelihood, as this method is less well known and some of the original publications are difficult to obtain. |
Which is best to use for paired ordinal data? The sign test or the “Svensson method”? There is no definitive answer. Both methods have their pros and cons. You have to make the choice yourself, and then you must be able to defend your decision.
A few more practical examples
- Seeing if the change in a single group is statistically significant:
This corresponds to what was called “Comparing change in one group. Possibly against a fixed (expected) value.” in the table above. Here, you compare each individual’s final value with their initial value. Do the differences deviate from the expected value of 0 (i.e., no change)? We choose to follow main approach C above and select the sign test option. In this case, you do not calculate an exact difference; you merely look at whether they have changed at all, and if so, in which direction. Let’s assume Dr. Citrus gave 63 individuals Vitamin C. He asked everyone at the baseline and after one year: “In general, would you say your health is…” Their responses were distributed such that 37 reported a better value after a year, 22 were unchanged, and 4 reported a worse value. You can now perform a sign test or McNemar’s test. In both of these tests, you ignore the 22 who remained unchanged. If we run the sign test, we get p = 0.0000001. This means that the group as a whole has improved, and the improvement cannot be explained by chance. The probability that we are wrong in making this claim is one in ten million. - Seeing if the difference in change between two matched groups is statistically significant:
Here, individuals are matched together in pairs. Let’s assume Dr. Citrus paired up a number of patients based on sex and age. One person in the pair is randomized to receive a placebo and the other to receive Vitamin C. We once again follow approach C described above. At the end of the study period, you count the number of pairs where the person who received Vitamin C improved more than the one who received the placebo, and vice versa. The pairs that changed by the same amount are ignored. You then run the calculations in the exact same way as in the example above, i.e., using a sign test or McNemar’s test. - Seeing if the difference in change between two unmatched groups is statistically significant:
In this example, we assume that Dr. Citrus had an unmatched control group that received sour candies (which were identical to the Vitamin C tablet in appearance and taste). We again follow approach C described above. The patients answer a questionnaire both initially and some time later after the “treatment.” The results were as follows:
| Vitamin C | “Placebo” | |
|---|---|---|
| Improved | 37 | 29 |
| Unchanged | 22 | 26 |
| Worse | 4 | 8 |
Because there is a natural order between “improved,” “unchanged,” and “worse,” you should compare the change between these two groups using the Mann-Whitney U test, rather than the Chi-square test (which completely ignores this inherent order). Even if you end up in a situation where absolutely no one is categorized as “unchanged” (which is actually quite common when looking at changes in a VAS), you should still use the Mann-Whitney U test. Regarding ties (shared ranks) and small sample sizes, you can read more about how to handle those on the dedicated page for the Mann-Whitney U test.