(the number of current visitors is automatically updated every 4 minutes)

If you want to share information about this web page...
This webpage provides an introduction to the concepts of correlation and regression. Reading this webpage will give you an understanding of what correlation and regression are, which is an important foundation for proceeding to learn more within statistics.
You will understand this webpage best if you have first read the pages Introduction to Statistics, Observations and Variables, Inferential statistics, Choosing statistical method, as well as the page on Covariation.
Mathematical models
Correlation and regression are about trying to describe reality using various mathematical formulas. Which mathematical formula can best describe reality? There are different mathematical models. The most common models are linear models, where one attempts to find the equation of a straight line that can describe reality. Most often, this concerns how one variable (let us call it y for the sake of simplicity) changes when one or more other variables (which we usually call x) change.
Introduction to correlation
Correlation is about how well two different variables covary. For the sake of simplicity, we can call the variables y and x. As an example, imagine that x is the age of a child and y is the child’s height. Each marker indicates the value of y and x respectively for each child (Figure 1). Here we see that if x is higher, it is likely that y is also higher (older children are taller than younger children).

Most often, we speak of linear correlation, that is, we see how well the covariation between these two variables resembles a straight line. This line is called a regression line (Figure 2).

Correlation coefficient
In correlation analysis, the computer calculates a correlation coefficient (=r). It tells us how close to a linear relationship we have in our sample. If the correlation coefficient is close to zero, there is no linear relationship (though there may be a non-linear relationship). The further the coefficient deviates from zero, the stronger the linear relationship. At most, the coefficient can deviate from zero to +1 or -1. At +1, there is a perfect linear relationship that is positive, i.e., when x increases, y also increases. With a correlation coefficient close to -1, the reverse applies, i.e., when x increases, y decreases. In Figure 2 above, we see that our sample lies quite close to our regression line. In that example, the correlation coefficient becomes 0.98, which suggests a strong linear relationship.
Now, one might wonder what the correlation coefficient would have been if we only had two crosses in diagrams 1 and 2. Let us play with the idea that we keep the crosses with the lowest and highest x-values, respectively. If we then connect these two crosses (which perhaps represent two patients), we see that the line between them fits perfectly, i.e., no cross lies outside the regression line (Figure 3).

In Figure 3, the correlation coefficient is 1.0. Is it really sufficient with only two measurements (two patients) to say that a perfect linear relationship exists between two variables?
Hypothesis testing of the correlation coefficient
Our assumption that there is a correlation between y and x in Figure 2 and Figure 3 is a hypothesis. The hypothesis is thus that there is a correlation in reality. Now we shall test if the hypothesis is correct. Since the truth in statistics is not black and white, this means estimating the uncertainty in our hypothesis using a p-value. We do this by performing a hypothesis test of our correlation coefficient. There are tables where one can see which p-value our correlation coefficient corresponds to. In the table, one needs to know the correlation coefficient and the number of examined individuals. Based on these two facts, the table gives a p-value. Computer programs that calculate the correlation coefficient can also provide these p-values automatically.
In our first example (Figure 1) with a correlation coefficient of 0.98 and with 8 examined individuals, the p-value becomes <0.001. We could claim that there is a relationship between variable x and y in the 8 examined individuals and the probability that we are wrong when we claim this is <0.1% or less than 1 in 1000 (strictly speaking, this means that the probability of obtaining this result if the null hypothesis were true is <0.1%). In our next example (Figure 3) with a correlation coefficient of 1.0 and with 2 examined individuals, the p-value becomes high. This means that the uncertainty in our statement, that there is a relationship between variable x and y, is maximal.
Generalised linear models (GLM)
The regression line (see Figure 2) is an attempt to mimic reality using a mathematical model. The absolutely most common mathematical model, which is also used in Figure 2, is the equation of a straight line. This is called linear regression. There are also other variants called non-linear regression models (described briefly further down). Since linear models are what are used most often, most energy is focused on explaining these.
Introduction to generalised linear regression
The most common and simplest mathematical model used is a straight line. If one only has one independent variable (just one x), the formula for this line can be written in various ways (that are all the same):
y = a + ßx
y = α + ßx
y = ß0 + ß1x
y = ß1x + ß0
y = mx + b
(…and a few more alternatives all expressing the same)
In the formula, y is a variable (for example, body height) and x is another variable (for example, age). a and b are constants, i.e., fixed numbers. The values of a and b determine what the line looks like. The constant a is usually called the intercept and b the regression coefficient. The line/formula can then be used to predict the value of y if one knows x. For example, we could predict the height of children if we had the exact values for a and b. The conditions for making such predictions are that:
- there is a linear relationship between y and x
- we stay within the intervals of x-values that have been studied and found to have a linear relationship with y. For example, it may be that body height and age have a linear relationship between 4–12 years of age, but outside that age interval, the relationship is not linear (with the same values for a and b).
One can let a computer calculate values for a and b and thereby describe a formula for a linear relationship between two variables, x and y, regardless of whether a linear relationship actually exists between these variables or not. It is therefore important to know if a linear relationship really exists. This is determined by, in the following order:
- Looking at the data with a scatter plot.
- If the scatter diagram suggests a linear relationship, performing a correlation analysis.
- If the correlation analysis says that x and y correlate, proceed to perform a regression to obtain values for a and ß.
Developing a regression line using the method of least squares
It is common to start by plotting how the two variables relate to each other using a scatter diagram (Figure 1 above). The value of variable x and the value of variable y meet at a cross. In such a diagram, each cross represents two observations on the same individual (for example, age and body height). Next, one draws a line that appears to fit to describe the relationship between variable y and variable x (Figure 2 above).
The line (usually called the regression line) can, of course, be drawn in slightly different ways. Which line best describes the relationship between x and y? The most common method for determining the best line is called the method of least squares. One can imagine a multitude of different lines to describe the relationship between x and y. Each of these lines can be tested. For every point/cross (for every patient, if patients are being examined), one takes the square of the difference between the y-value of the point/cross and the y-value of the proposed line. The reason the differences are squared is to eliminate the problem that approximately half of the differences lie above zero and approximately half below zero (a few may fall exactly on zero). The differences are often called residuals. All these squared differences (residuals) are summed, and the result is called SSE (Sum of the squared errors). SSE is also called the residual sum of squares. The line that yields the lowest SSE is the best.
Hypothesis testing of the regression coefficient
When we develop our mathematical model (our line), it is constructed from a sample. Our calculated values for the constants a and b are therefore estimates. Reality (the large population from which the sample was drawn) may look slightly different. To estimate the uncertainty, one can calculate the standard deviation and confidence intervals for a and b, respectively. Another way is to perform a hypothesis test. We can regard our developed regression line with fixed values for “a” and “b” as a hypothesis. There are actually several hypotheses contained within a simple linear regression:
- That reality can be likened to a straight line at all.
- That the regression coefficient “b” is as we believe.
- That the intercept “a” is as we believe.
How to test the first hypothesis has been described above under the heading “Hypothesis testing of the correlation coefficient”. Various statistical programs can calculate a p-value as a measure of the probability that we are wrong when we claim that the regression coefficient and the intercept, respectively, have a certain fixed value.
Multiple generalised linear regression
The equation for a simple regression line has only one independent variable (just one x). One can imagine a mathematical model where one wants to describe how y varies depending on how several other variables (multiple x’s) vary. This results in a multiple regression model, and the principal formula for this is:
y = a + b1x1 + b2x2 + b3x3 …..e.t.c.
Here we have an intercept (a) and several regression coefficients (several different b’s). Simple regression can easily be visualized with a scatter diagram (Figure 1). A regression with two independent variables can be visualized with a three-dimensional (difficult to understand) diagram. Regressions with three or more independent variables cannot be visualized in diagram form.
In a multiple regression, we have several independent variables (multiple x’s). How many x’s should be included in the model? We might have conducted a study where we collected a large amount of different variables. Should all of these be used? There might be several hundred! The best approach is to have a reasonable theory regarding which variables are relevant to include. If such a theory is lacking, one may have to conduct a “fishing expedition,” i.e., let the computer investigate all available variables and sift out the most significant ones. The most common options when letting the computer choose are:
- All possible regressions
- Forward selection
- Backward elimination
- Stepwise regression
- Regularized regression
Coefficient of determination
The coefficient of determination (=r2 =r^2 =R2) is a coefficient that indicates how large a part of the variations in the dependent variable (y) can be explained by variations in the independent variables (x), provided that the relationship between these x and y is linear. The coefficient of determination is often called the degree of explanation (or explanatory power).
In simple linear regression, the coefficient of determination can be calculated by squaring the correlation coefficient (r). For multiple regression, one calculates the coefficient of determination by taking the sum of squares for the regression model (Regression/Model – Sum of squares) divided by the total sum of squares (Total – Sum of squares). In practice, this is the sum of squares for differences between our regression line and the mean value for y (what the model explains) divided by the sum of squares for differences between the actual value for y and the mean value for y (the total variation).
In our first example (Figure 1+2), the coefficient of determination becomes 0.98 squared, i.e., 0.96. This means that 96% of the variation in y can be explained by changes in x. The remaining 4% is unexplained, i.e., it depends on other factors that our mathematical model cannot explain. The coefficient of determination has a tendency to increase the more independent variables (the more different x’s) we include in our mathematical model. At the same time, more x’s also imply an uncertainty that we introduce spurious relationships which give us a falsely high R^2. There is a corrected R^2 that takes this into account. It is called ra^2 or “adjusted R-square”. The coefficient ra^2 therefore often decreases the more independent variables (x’s) one adds to one’s mathematical model.
A bird’s-eye view of different types of generalised linear regression models
One or more variables are designated as “dependent variables” (denoted by “y” in the formulas above). By this, it is meant that they are thought to depend on and change when one or more independent variables change. One speaks of different types of regression depending on whether one has one or more dependent and independent variables, respectively :
- Simple regression: One dependent and one independent variable (one “y” and one “x”).
- Multiple regression: (=multivariable regression) More than one independent variable (one “y” and multiple “x’s”).
- Multivariate regression: More than one dependent variable (multiple “y’s” and one “x”).
- Multivariate (multiple) regression (=multivariate (multivariable) regression) More than one dependent variable as well as more than one independent variable (multiple “y’s” and multiple “x’s”). The designation “multivariate” trumps the designation “multiple.” By this, it is meant that if both are included, “multiple” is omitted because it is assumed that most multivariate analyses are also multiple.
It is common for the term ‘multivariate regression’ to be incorrectly used when ‘multiple regression’ is meant. Furthermore, regression is classified according to the measurement scale used for the dependent variable:
- Standard linear regression: The dependent variable is measured using an interval or ratio scale.
- Poisson regression: The dependent variable is measured using count data.
- Logistic regression: The dependent variable is almost always binary / dichotomous. There are exceptions in ‘ordinal logistic regression’ (when the dependent variable is measured using an ordinal scale) or ‘multinomial logistic regression’ (in the case of more than two independent outcomes that are not ordered). Read more on the page about logistic regression.
- Cox regression = Cox proportional hazards regression: The dependent variable concerns time to an event, for example, recovering from a disease, contracting a disease, or death. The dependent variable actually consists of two variables: one that indicates whether an event of interest has occurred (often coded as 1) or not (often coded as 0). The other variable indicates the time an individual has been followed up regardless of whether the event has occurred or not.
| Simple regression | Multiple regression = multivariable regression | Multivariate regression | Multivariate (multipel) regression* | |
|---|---|---|---|---|
| Standard linear regression** | Simple standard linear regression = Unadjusted standard linear regression | Multiple standard linear regression = multivariable standard linear regression = adjusted standard linear regression | Multivariate standard linear regression | Multivariate (multiple) standard linear regression* |
| Poisson regression | Simple Poisson regression | Multiple Poisson regression | Multivariate Poisson regression | Multivariate (multiple) Poisson regression* |
| Logistic regression | Simple logistic regression = unadjusted logistic regression | Multiple logistic regression = multivariable logistic regression = adjusted logistic regression | Multivariate logistic regression (an alternative method could be multivariate Probit regression) | Multivariate (multiple) logistic regression* (an alternative method could be multivariate Probit regression) |
| Cox regression | Simple Cox regression = Simple proportional Hazards regression | Multiple Cox regression = multivariable Cox regression = multivariable proportional hazards regression | Multivariate Cox regression | Multivariate (multiple) Cox regression* |
* The designation “multivariate” trumps the designation “multiple.” This means that if both apply, “multiple” is omitted because it is assumed that most multivariate analyses are also multiple. For example, one does not write “Multivariate multiple Cox regression,” but simply “Multivariate Cox regression”.
** Standard linear regression is often shortened to just “linear regression” omitting “standard”.
You do not need to be familiar with all the variants in the table above. The most common types of linear regressions are ‘Simple standard linear regression’, ‘Multiple standard linear regression’, ‘Simple Poisson regression’, ‘Multiple Poisson regression’, ‘Simple logistic regression’, ‘Multiple logistic regression’, ‘Simple Cox regression’, and ‘Multiple Cox regression’.
Non-linear regression
It is not uncommon in simple standard linear regression to find that the correlation coefficient is low and non-significant. The fact that our correlation coefficient is not statistically significant does not mean that reality cannot be described by a mathematical model. If our linear model does not fit, perhaps a non-linear model will. There are many different variants of non-linear models, for example polynomial approximations. If one has only one independent variable (one x), it is wrong not to first look at the relationship between x and y in a scatter diagram before performing the regression analysis. Let us assume that we incorrectly perform a simple linear regression (Figure 4).

(=polynomapproximation av 1:a graden)
Om vi ber datorn göra en linjär regressionsanalys med y som beroende variabel och x som oberoende spottar datorn ur sig följande formel:
y = 3,097 – 0,2566x
Vi finner en korrelationskoefficient på 0,094 (determinationskoefficient 0,0089) och p-värdet för korrelationskoefficienten blir högt (1,0). Även om formeln ovan ser vacker och förtroendeingivande ut är den alltså helt värdelös. Istället för att ge upp kan man prova andra matematiska modeller (Figur 5).
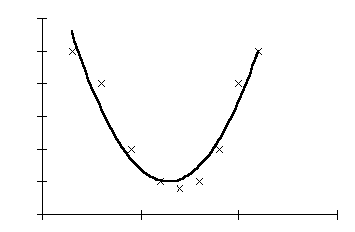
Figure 5 gives an example of how the same sample can be described using a quadratic equation, which mathematically is:
y = 8,818 – 12,191x + 4,753x2
When we transition from a simple linear regression to a second-degree polynomial regression, the degree of explanation (the coefficient of determination) increases from 0.0089 to 0.9285. We now have a mathematical model that explains reality much better. One can try to see if one can find other mathematical models that describe reality even better (Figure 6).

Figure 6 provides an example of how the same sample can be described using a sixth-degree equation. The formula for a 6th-degree polynomial regression is in principle:
y = a + b1x – b2x2 + b3x3 – b4x4 + b5x5 – b6x6
and in the example (Figure 6) it becomes:
y = – 9,6853 + 111,71x – 303,44x2 + 383,01x3 – 254,3x4 + 85,798x5 – 11,512x6
When we transition from a polynomial approximation of the second degree to a polynomial regression of the sixth degree, the degree of explanation (coefficient of determination) increases from 0.9285 to 0.9997. We now have a mathematical model that explains reality even better.
All this sounds good. Let us always use 6th-degree polynomial approximations! The problem with these advanced mathematical constructions is that they are difficult to interpret. Experience suggests that many measurable covariations, especially biological ones, resemble linear equations fairly well, at least as long as one stays within reasonable limits, preferably within the values of x that have been investigated.
The overwhelming majority of mathematical models used are linear models. It is uncommon, at least in medical contexts, to use more complicated models. It should also be pointed out that non-linear models constitute advanced statistics and generally require the assistance of a statistician.